What happens when a gang of amateur photographers, turned into amateur developers, joined by a bunch of back-end developers who develop libraries for developers, decide to work without method nor structure on an industry software for end-users, which core competency (colorimetry and psychophysics) lies somewhere between a college degree in photography and a master’s degree in applied sciences, while promising to deliver 2 releases each year without project management ? All that, of course, in a project where the founders and the first generation of developers moved on and fled ?
Guess !
Degrading basic features
The 2020’s are 40 years too late to re-invent interaction paradigms between user and computer, being it how we use a keyboard and a mouse to drive the interface or the behaviour of a file browser. Since the 1980’s, all the general-audience computer appliances have converged toward more or less unified semantics, where the escape key closes the current application, double-click opens files and the mouse wheel scrolls the current view. Darktable1 takes an ill-placed pleasure to ignore all that and the recent changes worsen things : it is now mandatory to read the documentation to achieve tasks as simple as sorting files or assigning keyboard shortcuts to GUI actions.
Module groups
Everything begins with the overhaul of the modules groups , in 2020, which hides the decision of not deciding of an unified module order.
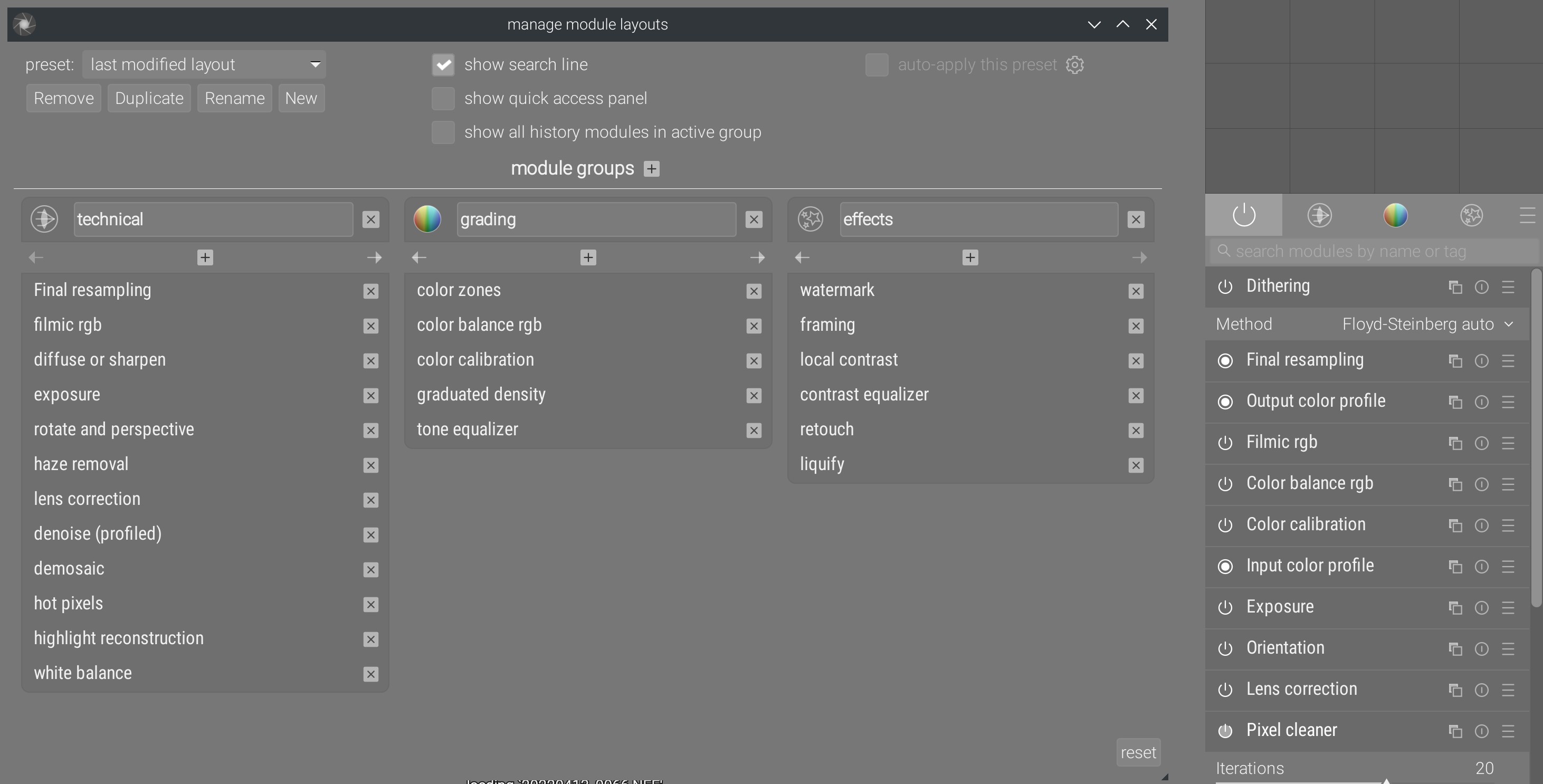
Since 2018 , I fight to clean up the graphical interface of Darktable, and in particular the module organization. A graphical interface should promote best practices by laying out tools in the typical order they should be used. Bad practices are those which increase the risk of colorimetric inconsistencies or of circular editing, where one must go back to repercute changes made later, even though bad practices can work in simple cases. In the context of image processing, highly-technical task where a lot of things are hidden to the end-users beneath the GUI, best practices also enable poorly-qualified persons to use the software in a way that reduces the probability of mistakes.
This order of using is mostly dictated by technical considerations like the order of application of modules in the pipeline sequence and the use of drawn and parametric masks, which effect depends on upstream modules. Ignoring these considerations is equivalent to looking for trouble, even though the hot trend in the 2010’s and 2020’s is to believe that digital technologies work detached of any material reality for the sole happiness of the user.
For example, the constrained imposed upon the pipeline design to allow an arbitrary order of module use creates mathematically unsolvable problems regarding the computation of mask nodes coordinates, and no programmed solution is possible (aside from relaxing that constraint) because maths said no.
Except that a significant part of the programmer-users revolving around the project on Github and on the dev mailing-list stay convinced that there is no good or bad workflow, only personal preferences, which is probably true when you practice an art without time constraint, budget constraint or result constraint. As such, modules should be able to be reordered at will, being in the pipeline or in the workflow. The confusion comes from the fact that non-destructive editing is wrongfully seen as asynchronous (which would almost be the case if we didn’t use masks nor blending modes) whereas the pixel pipeline is sequential and closer to a layer logic, as we find it in Adobe Photoshop, Gimp, Krita, etc.
Decoupling the modules order in the GUI from the pipeline order is equivalent to enabling every use, even pathological, and forces to write pages and pages of documentation to warn, explain what to do, how and why ; documentation that nobody will read to end up asking in loop the same questions every week on every forum.
In this story, everyone looses their time thanks to an interface design trying to be so flexible that it can’t be made safe and robust by default. In the human body, every joint as some degrees of freedom along certains axes ; if every joint could revolve 340 ° around each axis of the 3D space, the structure would be instable for being too flexible, and unable to work with high loads. The metaphor holds in industry software. We swim in the FLOSS cargo cult , where people love to have the illusion of choice, that is being offered many options of which most are unusable or dangerous, at the expense of simplicity (KISS ), and where the majority of users don’t understand the implications of each option (and don’t have the slightest desire to understand).
In the absence of a consensus over the interface module ordering, a complicated tool, brittle and heavy was introduced at the end of 2020 to allow each user to configure the layout of modules in tabs. It provides many useless options and stores the current layout in the database, using the translated name of modules, meaning changing the UI language makes you loose your presets. Entirely configurable, it lets user decide how to harm themselves, without any best practices guide. This garbage is coded with 4000 lines cheerfully mixing SQL requests in the middle of interface GTK code , and presets are created through redundant compiler macros , whereas modules have had a binary flag forever, allowing to set their default group… modularly.
More important, it replaces a simple and efficient feature, available until Darktable 3.2 :
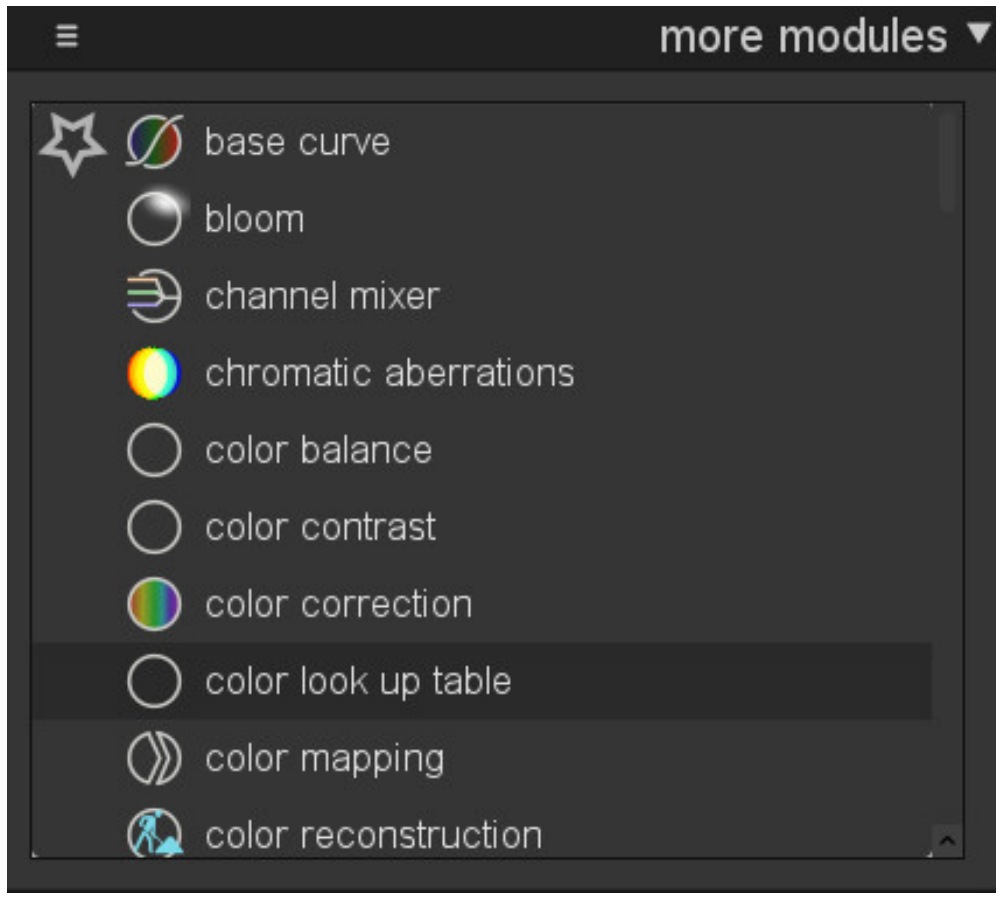
One click over the module name enables it, a second adds it to the column of favorites, a third hides it from the interface. Everything allowing presets and storing the current layout in simple text into the darktablerc file. Simple and robust, coded over 688 lignes of legible and well-structured code, the feature was therefore not amusing enough for the middle-aged dilettante developer, and it was urgent to replace it by a labyrinthine system.
Keyboard shortcuts
In 2021 has been added what I call the great MIDI turducken . The goal is to extend the interface of keyboard shortcuts (already extended in 2019 to support “dynamic shortcuts”, allowing to combine mouse and keyboard actions), to support MIDI devices and… video game controllers.
At the end of 2022, that is one and half year after this feature, in the survey I conducted , less than 10 % of users own a MIDI device, and only 2 % use it with Darktable. To compare with the 45 % of users who own a graphic tablet (Wacom-like), which support in Darktable is still so flawed that only 6 % use it. Notwithstanding the poor priority management, what I don’t tolerate here is the edge effects introduced by this change and the global cost it had, starting with the fact that it doesn’t import user-defined shortcuts from versions ealier than 3.2, and it makes the configuration of new shortcuts terribly complicated.
Before the great turducken, only a limited list of GUI actions could be mapped to keyboard or mixed (keyboad + mouse) shortcuts. This list was manually curated by developers. The great MIDI turducken allows to map every GUI actions to shortcuts, presenting users with a list of several thousands of configurable entries, in which it’s difficult to find the only 3 you really need, and the text search engine is too basic to be helpful :
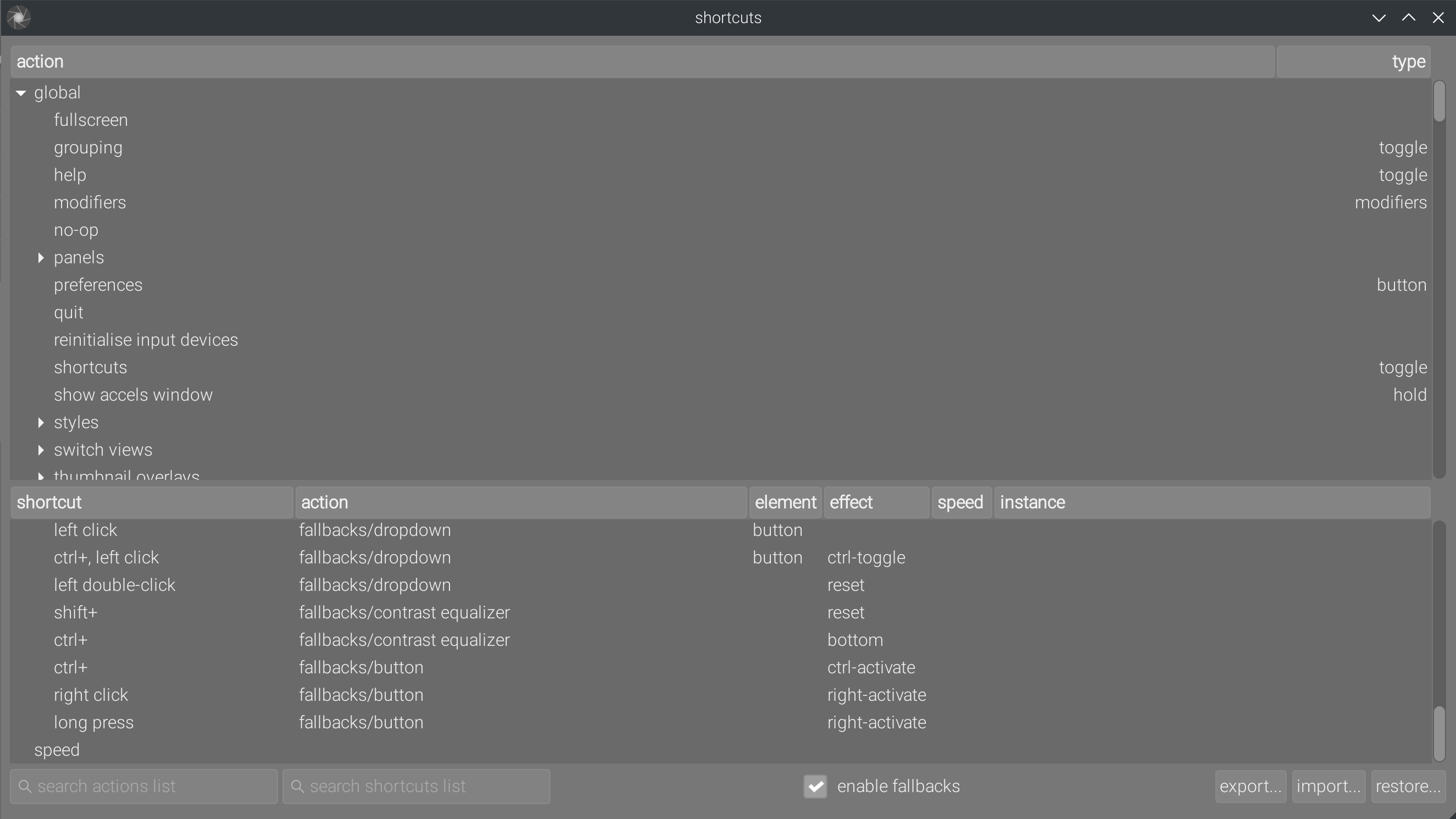
Note the use of “effects”, on which the documentation is of no help. It’s only by deduction (because the code is not commented either ) that I ended up understanding they are emulations of typical desktop interactions (mouse and keyboard) destined to be used with MIDI devices and gamepad controllers (but you still need to explain to me what Ctrl-Toggle, Right-activate or Right-Toggle mean in terms of typical destkop interaction).
What is unacceptable is that the use of the numeric keypad is broken by design , noticeably to attribute numbered ratings (stars) to thumbnails in lighttable. Indeed, the key modifiers (numlock and capslock) are not properly decoded by the thing, and numbers are treated differently whether they are input from the typical “text” keyboard or from the numeric keypad. So the 1 from the numpad is decoded Keypad End, no matter the state of the numlock. This is how I had to configure number shortcuts on a French BÉPO keyboard and to duplicate the configuration for the numpad :
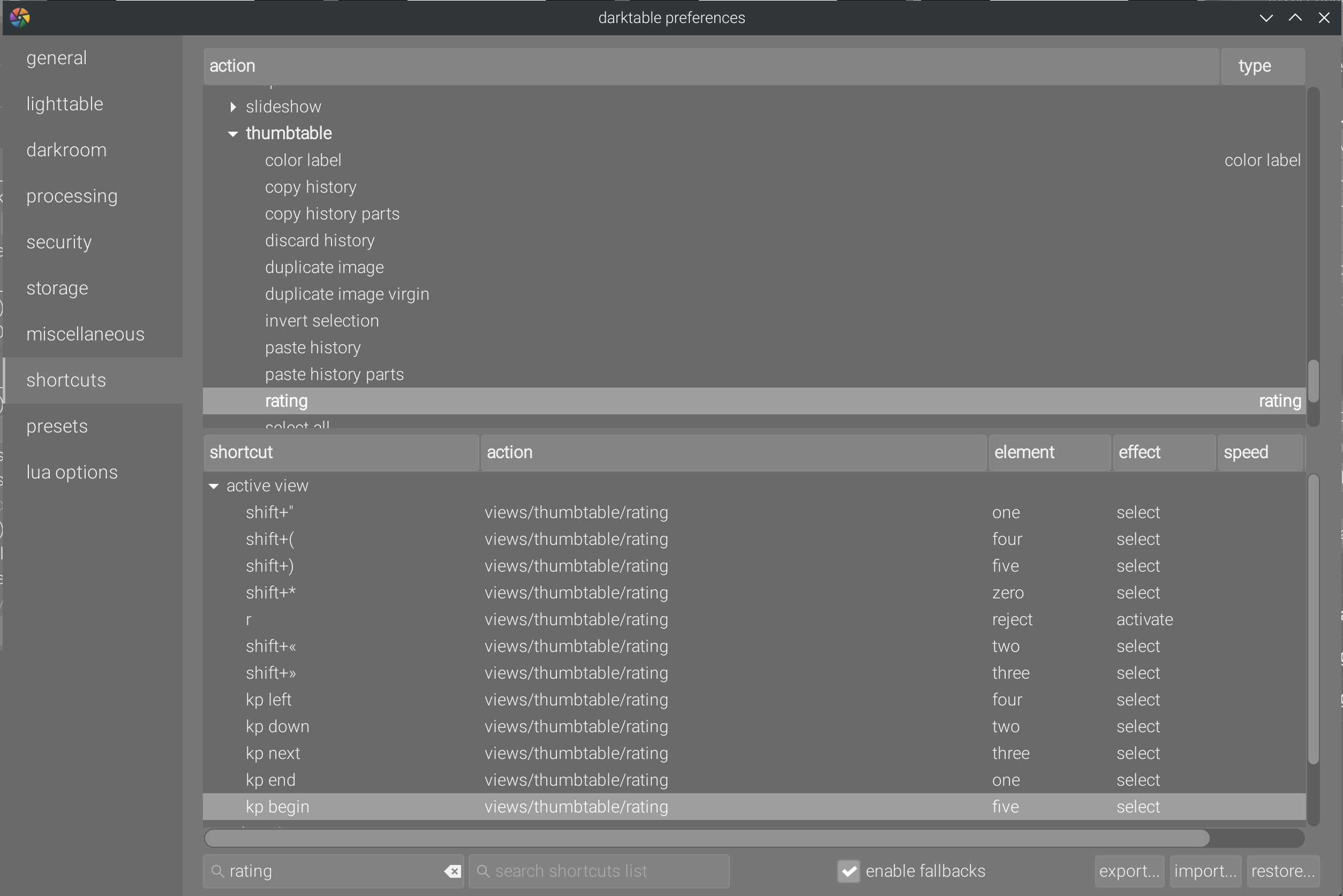
You just have to remember that Shift+" and Kp End both mean 1 and remember to duplicate all shortcuts for the numpad and the rest of the keyboard. In short, we break a basic user expectation, and we send design critics to hell. The regression is mentionned on all Darktable forums but seems to bother nobody.
The fix of this bug this feature has been made in Ansel and the numeric pad keys are remapped to standard keys directly in the code , for a total of 100 lines of code including comments. Doing this correction has been very hard indeed : I read the Gtk documentation and took their example line by line. 2 years spent waiting for that…
The cherry on the sunday is, one more time, we replaced 1306 lines of clear and structured code by a monstruosity of close to 4400 lines , with gems like :
- the
whileloop of death (source ) :
1 gboolean applicable;
2 while((applicable =
3 (c->key_device == s->key_device && c->key == s->key && c->press >= (s->press & ~DT_SHORTCUT_LONG) &&
4 ((!c->move_device && !c->move) ||
5 (c->move_device == s->move_device && c->move == s->move)) &&
6 (!s->action || s->action->type != DT_ACTION_TYPE_FALLBACK ||
7 s->action->target == c->action->target))) &&
8 !g_sequence_iter_is_begin(*current) &&
9 (((c->button || c->click) && (c->button != s->button || c->click != s->click)) ||
10 (c->mods && c->mods != s->mods ) ||
11 (c->direction & ~s->direction ) ||
12 (c->element && s->element ) ||
13 (c->effect > 0 && s->effect > 0 ) ||
14 (c->instance && s->instance ) ||
15 (c->element && s->effect > 0 && def &&
16 def->elements[c->element].effects != def->elements[s->element].effects ) ))
17 {
18 *current = g_sequence_iter_prev(*current);
19 c = g_sequence_get(*current);
20 }- The
switchcasecontainingifnested on 2 levels (source ) :
1 switch(owner->type)
2 {
3 case DT_ACTION_TYPE_IOP:
4 vws = DT_VIEW_DARKROOM;
5 break;
6 case DT_ACTION_TYPE_VIEW:
7 {
8 dt_view_t *view = (dt_view_t *)owner;
9
10 vws = view->view(view);
11 }
12 break;
13 case DT_ACTION_TYPE_LIB:
14 {
15 dt_lib_module_t *lib = (dt_lib_module_t *)owner;
16
17 const gchar **views = lib->views(lib);
18 while(*views)
19 {
20 if (strcmp(*views, "lighttable") == 0)
21 vws |= DT_VIEW_LIGHTTABLE;
22 else if(strcmp(*views, "darkroom") == 0)
23 vws |= DT_VIEW_DARKROOM;
24 else if(strcmp(*views, "print") == 0)
25 vws |= DT_VIEW_PRINT;
26 else if(strcmp(*views, "slideshow") == 0)
27 vws |= DT_VIEW_SLIDESHOW;
28 else if(strcmp(*views, "map") == 0)
29 vws |= DT_VIEW_MAP;
30 else if(strcmp(*views, "tethering") == 0)
31 vws |= DT_VIEW_TETHERING;
32 else if(strcmp(*views, "*") == 0)
33 vws |= DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
34 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
35 views++;
36 }
37 }
38 break;
39 case DT_ACTION_TYPE_BLEND:
40 vws = DT_VIEW_DARKROOM;
41 break;
42 case DT_ACTION_TYPE_CATEGORY:
43 if(owner == &darktable.control->actions_fallbacks)
44 vws = 0;
45 else if(owner == &darktable.control->actions_lua)
46 vws = DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
47 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
48 else if(owner == &darktable.control->actions_thumb)
49 {
50 vws = DT_VIEW_DARKROOM | DT_VIEW_MAP | DT_VIEW_TETHERING | DT_VIEW_PRINT;
51 if(!strcmp(action->id,"rating") || !strcmp(action->id,"color label"))
52 vws |= DT_VIEW_LIGHTTABLE; // lighttable has copy/paste history shortcuts in separate lib
53 }
54 else
55 fprintf(stderr, "[find_views] views for category '%s' unknown\n", owner->id);
56 break;
57 case DT_ACTION_TYPE_GLOBAL:
58 vws = DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
59 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
60 break;
61 default:
62 break;
63 }- The nested
switchcaseof the demon, with additive clauses sneakily hidden (source ) :
1case DT_ACTION_ELEMENT_ZOOM:
2 ;
3 switch(effect)
4 {
5 case DT_ACTION_EFFECT_POPUP:
6 dt_bauhaus_show_popup(widget);
7 break;
8 case DT_ACTION_EFFECT_RESET:
9 move_size = 0;
10 case DT_ACTION_EFFECT_DOWN:
11 move_size *= -1;
12 case DT_ACTION_EFFECT_UP:
13 _slider_zoom_range(bhw, move_size);
14 break;
15 case DT_ACTION_EFFECT_TOP:
16 case DT_ACTION_EFFECT_BOTTOM:
17 if((effect == DT_ACTION_EFFECT_TOP) ^ (d->factor < 0))
18 d->max = d->hard_max;
19 else
20 d->min = d->hard_min;
21 gtk_widget_queue_draw(widget);
22 break;
23 default:
24 fprintf(stderr, "[_action_process_slider] unknown shortcut effect (%d) for slider\n", effect);
25 break;
26 }Programmers understand what I’m talking about ; for the others, just know that I don’t understand more than you what this does : it’s shit code, and if several bugs are not hidden in there, it will be pure luck. Hunting bugs in this shithole is sewer’s bottom archaelogy, all the more considering that Darktable does not have a developer documentation and, in the absence of meaningful comments in the code, any modification of the aforementionned code will necessarily start with a reverse-engineering phase becoming harder and harder as time goes by.
The true problem of this kind of code is that you can’t improve it without rewriting it more or less entirely : to fix it, you first need to understand it, but the reason why it needs to be fixed is precisely that it’s not understandable and dangerous long-term. We call that technical debt . In short, all the work invested on this feature will create extra work because it is unreasonable to keep that kind of code in the middle of a code base of several hundreds of thousands of lines and expect it to not blow up in our face one day.
It’s all the more ridiculous in the context of an open-source/free application where the bulk of the staff is non-trained programmers. Clever developers write code understandable by idiots, and the other way around.
Collection filters
Until Darktable 3.8, the collection filters, at the top of the lighttable, were used to temporarilly restrict the view on a collection. The collection is an extraction of the photo database based on certain criteria, the most common being extracting the content of a folder (which Darktable calls “filmroll” to confuse everybody, because a filmroll is actually a folder’s content displayed as a flat list instead of a tree - many people wrongfully thing that Darktable has no file manager).
Having been a Darktable user for more than a decade, I have a database of more than 140.000 entries. Extracting a collection among these 140.00 pictures is a slow operation. But my folders rarely contain more than 300 pictures. Filtering, for example, the pictures rated 2 stars or more, in a collection of 300 files, is fast because it is a subset of 300 elements. And switching from a filter to another is fast too. The filter is only a partial or total view of a collection, optimized for a fast and temporary start-and-go usage.
Under the pretense of refactoring the filtering code, which took all in all 550 lines , the chief Gaston Lagaffe made it a vocation to break this model to turn collection filters into basic collections, by mean of more than 6.000 lines of code , not counting the countless bugfixes that only added more lines2. All that, as usual, highly configurable and redundant with the classical collections module , which remained there, and served by icons so cryptic that they had to add text tooltips on hover to clarify what they mean..
In this quality code, we will found the endless while under the switch case in the if in the if in the for (source ) :
1for(int k = 0; k < num_rules; k++)
2 {
3 const int n = sscanf(buf, "%d:%d:%d:%d:%399[^$]", &mode, &item, &off, &top, str);
4
5 if(n == 5)
6 {
7 if(k > 0)
8 {
9 c = g_strlcpy(out, "<i> ", outsize);
10 out += c;
11 outsize -= c;
12 switch(mode)
13 {
14 case DT_LIB_COLLECT_MODE_AND:
15 c = g_strlcpy(out, _("AND"), outsize);
16 out += c;
17 outsize -= c;
18 break;
19 case DT_LIB_COLLECT_MODE_OR:
20 c = g_strlcpy(out, _("OR"), outsize);
21 out += c;
22 outsize -= c;
23 break;
24 default: // case DT_LIB_COLLECT_MODE_AND_NOT:
25 c = g_strlcpy(out, _("BUT NOT"), outsize);
26 out += c;
27 outsize -= c;
28 break;
29 }
30 c = g_strlcpy(out, " </i>", outsize);
31 out += c;
32 outsize -= c;
33 }
34 int i = 0;
35 while(str[i] != '\0' && str[i] != '$') i++;
36 if(str[i] == '$') str[i] = '\0';
37
38 gchar *pretty = NULL;
39 if(item == DT_COLLECTION_PROP_COLORLABEL)
40 pretty = _colors_pretty_print(str);
41 else if(!g_strcmp0(str, "%"))
42 pretty = g_strdup(_("all"));
43 else
44 pretty = g_markup_escape_text(str, -1);
45
46 if(off)
47 {
48 c = snprintf(out, outsize, "<b>%s</b>%s %s",
49 item < DT_COLLECTION_PROP_LAST ? dt_collection_name(item) : "???", _(" (off)"), pretty);
50 }
51 else
52 {
53 c = snprintf(out, outsize, "<b>%s</b> %s",
54 item < DT_COLLECTION_PROP_LAST ? dt_collection_name(item) : "???", pretty);
55 }
56
57 g_free(pretty);
58 out += c;
59 outsize -= c;
60 }
61 while(buf[0] != '$' && buf[0] != '\0') buf++;
62 if(buf[0] == '$') buf++;
63 }and other if nested over 2 levels inside switch case necessary to support the keyboard shortcuts (source ).
This last fucking crap was the straw that broke the camel’s back and made me fork Ansel. I refuse to work on a ticking bomb in a team that doesn’t see the problem and plays with code over their spare time. Coding may amuse them, not me. And fixing shit done by irresponsible kids twice my age, especially when they break stuff I cleaned up 3 or 4 years ago, infuriates me.
Lighttable
The lighttable underwent 2 nearly-full rewritings, the first in early 2019 and the second in late 2019, which added many disputable features like the culling view .
Quickly, the culling mode is divided into 2 submodes : dynamic and static, which manage the number of images differently. Many users still haven’t understood the difference 4 years later. We therefore have the default view (file manager), the zoomable lighttable (that nobody uses), the static culling, the dynamic culling, and the preview mode (a single full-screen picture).
Then, more display options are added to thumbnails in lighttable, allowing to define overlays : basic permanent overlays, extended EXIF permanent overlays, the same but only on hover, and finally the timed hovered overlays (with a configurable timer).
The UI code rendering thumbnails and their overlays must therefore take into account 5 different views and 7 display variants , that is 35 possible combinations. The code ensuring proper resizing of thumbnails thus needs a total of 220 lines .
But it doesn’t stop there, because the code rendering the thumbnails GUI is shared also with the “filmstrip” bottom bar, which actually makes 36 possible combinations in thumbnail rendering. Multiplied by 3 GUI themes of different base colors, that makes 108 sets of CSS instructions to fully style the GUI… of which many were forgotten in Darktable 4.0 graphic overhaul , and how could it be differently ?
In Darktable 2.6, we had 4193 lines for the pack, which had only the filemanager, zoomable lighttable and fullscreen preview views, with only 2 modes of thumbnails overlays (always visible or visible on hover) :
- 2634 lines views/lighttable.c for the lighttable and the thumbnail rendering,
- 1124 lines in libs/tools/filmstrip.c for the filmstrip par, which partially duplicates the lighttable code for the thumbnail rendering,
- 435 lines in libs/tools/global_toolbox.c , for the button menu allowing to enable or disable thumbnails overlays.
After Darktable 3.0 and the addition of culling modes, we get 6731 lines :
- 5149 lines views/lighttable.c ,
- 1177 lines libs/tools/filmstrip.c ,
- 405 lines libs/tools/global_toolbox.c .
After Darktable 3.2 and the additions of the 7 variants of highly-configurable overlays and some code refactoring, we get 8380 lines :
- 1463 lines in views/lighttable.c ,
- 1642 lines in dtgtk/culling.c , where the culling view features were detached,
- 2447 lines in dtgtk/thumbtable.c , where the thumbnails containers are managed for the lighttable and the filmstrip,
- 1736 lines in dtgtk/thumbnail.c , where the thumbnails themselves are managed,
- 169 lines in dtgtk/thumbnail_btn.c , where the specific thumbnails buttons are declared,
- 115 lines in libs/tools/filmstrip.c ,
- 808 lines in libs/tools/global_toolbox.c .
In Darktable 4.2, after the correction of many bugs, we get to a total of 9264 lines :
- 1348 lines in views/lighttable.c ,
- 1828 lines in dtgtk/culling.c ,
- 2698 lines in dtgtk/thumbtable.c ,
- 2093 lines in dtgtk/thumbnail.c ,
- 166 lines in dtgtk/thumbnail_btn.c ,
- 109 lines in libs/tools/filmstrip.c ,
- 1022 lines in libs/tools/global_toolbox.c .
The number of lines (especially in code taking an ill-placed pleasure in ignoring programming best practices) is a direct indicator of the difficulty to debug anything in there, but also an indirect indicator (in the specific case of GUI code) of CPU load required to run the software.
Indeed, if you start darktable -d sql and you hover a thumbnail in lighttable, you will get in terminal :
1140.8252 [sql] darktable/src/common/image.c:311, function dt_image_film_roll(): prepare "SELECT folder FROM main.film_rolls WHERE id = ?1"
2140.8259 [sql] darktable/src/common/image.c:387, function dt_image_full_path(): prepare "SELECT folder || '/' || filename FROM main.images i, main.film_rolls f WHERE i.film_id = f.id and i.id = ?1"
3140.8271 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
4140.8273 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
5140.8275 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
6140.8277 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
7140.8279 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
8140.8280 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
9140.8282 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
10140.8284 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
11140.8286 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
12140.9512 [sql] darktable/src/common/act_on.c:156, function _cache_update(): prepare "SELECT imgid FROM main.selected_images WHERE imgid=104337"
13140.9547 [sql] darktable/src/common/act_on.c:156, function _cache_update(): prepare "SELECT imgid FROM main.selected_images WHERE imgid=104337"
14140.9550 [sql] darktable/src/common/act_on.c:288, function dt_act_on_get_query(): prepare "SELECT imgid FROM main.selected_images WHERE imgid =104337"
15140.9552 [sql] darktable/src/libs/metadata.c:263, function _update(): prepare "SELECT key, value, COUNT(id) AS ct FROM main.meta_data WHERE id IN (104337) GROUP BY key, value ORDER BY value"
16140.9555 [sql] darktable/src/common/collection.c:973, function dt_collection_get_selected_count(): prepare "SELECT COUNT(*) FROM main.selected_images"
17140.9556 [sql] darktable/src/libs/image.c:240, function _update(): prepare "SELECT COUNT(id) FROM main.images WHERE group_id = ?1 AND id != ?2"
18140.9558 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"which means that 18 SQL requests are made against the database to fetch image information, and run everytime the cursor hovers a new thumbnail, for no reason since metadata didn’t change since the previous hovering.
In Ansel, by removing most options, I managed to spare 7 requests, which still doesn’t prevent duplicated requests but still improve the timings somewhat (timestamps are the figures starting each line) :
112.614534 [sql] ansel/src/common/image.c:285, function dt_image_film_roll(): prepare "SELECT folder FROM main.film_rolls WHERE id = ?1"
212.615225 [sql] ansel/src/common/image.c:356, function dt_image_full_path(): prepare "SELECT folder || '/' || filename FROM main.images i, main.film_rolls f WHERE i.film_id = f.id and i.id = ?1"
312.616499 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
412.616636 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
512.616769 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
612.616853 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
712.616930 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
812.617007 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
912.617084 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
1012.617205 [sql] ansel/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (133727) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
1112.617565 [sql] ansel/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (133727) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"The issue is that the source code nests SQL commands inside functions drawing the GUI, and untangling this mess through the different layers inherited from “refactoring” (supposed to simplify the code, but actually nope) is once again archaelogy. And if the issue had been fixed when the code was 6700 lines over 3 files, we wouldn’t be looking, 4 years later, for the causes in 2500 additionnal lines now spread in 7 different files (not counting .h files).
We are in the poster case where “refactoring” actually complexified code and where merging thumbnail code between filmstrip and lighttable only added more internal if (branches) nested on several levels, which complexify even more the structure, only to blindly follow the code reuse principle , which conflicts here with the modularity principle , which a skilled developer would have fixed with [inheritance](https://en.wikipedia.org/wiki/Inheritance_(object-oriented_programming) , because even if it’s not easy to do in C, it’s perfectly possible (actually, Darktable uses this principle in code from 2009-2010).
Cosmetics take over stability
Darktable 4.2 introduces the styles preview in darkroom. That would be awesome if styles were not deeply broken, when used with non-default pipeline order and multiple module instances. The problem is a clean and long-term solution involves directed graphs theory , and that’s where we lost our beloved copy-pasted code pissers.
In the same spirit, we have large inconsistencies on history copy-pasting in overwrite mode when default user presets are also used (especially in white balance module). But it’s far funnier to shit up the interface, so it will stay there for a long time.
Darktable 3.6 and 3.8 introduced many variants of the histogram : vectorscope, vertical waveform, advanced and exotic colorspaces. Except that if you launch darktable -d perf in terminal and open the darkroom, you will see a lot of
everytime you move the cursor in the window (and not even over the histogram). It is the histogram that gets redrawn at every interaction between cursor and window. The same problem affects many custom graphical widgets and its cause is unidentified. Note that it doesn’t affect Ansel, so the cause should be hidden somewhere in the 23.000 lines of code that I removed.
Twice, I tried to refactor the shitshow this feature became , but each time a new feature more urgent was pushed that invalidated my work. I simply gave up.
The rotting state of the histogram is such that a full rewrite would take less time than a refactoring, especially since the histogram is sampled way too late in the pipeline, in the screen colorspace, which makes the definition of an histogram colorspace null given that the gamut is clipped in screen colorspace no matter what. But guess what… Darktable 4.4 will have even more options, with the ability to define color harmonies (fundamental for geeks who paint by numbers and edit histograms).
It remains that, any time you move the cursor, a great number of useless recomputations are started for nothing. How bad is it ? I had the idea of measuring the CPU use of my system when idle, with the Linux tool powertop. The protocol is quite simple : a laptop (CPU Intel Xeon Mobile 6th generation), working on battery in powersave mode, backlighting set to minimum, open the app and touch nothing for 4 min, then monitor the global CPU consumption of the system as reported by powertop during the 5th minute :
- Base system (no app opened except for
powertopruning in a terminal) : 3.0 to 3.5 % CPU - Ansel :
- opened on lighttable : 2.9 to 3.4 % CPU,
- opened on darkroom : 3.8 to 4.5 % (before reverting module groups to Darktable 3.2),
- opened on darkroom : 3.0 to 3.5 % (after reverting module groups),
- Darktable :
- opened on lightable : 6.6 to 7.1 % CPU,
- opened on darkroom : 30.9 to 44.9 % CPU (no, it’s not a coma mistake),
I don’t understand what Darktable computes when we leave it open without touching the computer, because there is nothing to compute. Darktable in lighttable consumes by itself as much as the whole system (Fedora 37 + KDE desktop + password manager and Nextcloud client running in background), and it consumes 10 times as much as the whole system when opened in darkroom.
All this points towards very buggy graphical interface code. In Ansel, I removed a great part of the dirty code, without optimizing anything else, and these figures are only validating my choice : dirty code hides problems undetectable by reading it, and we simply can’t continue on this path.
I’m apparently the only one thinking it’s unacceptable to deprive the pixel pipeline of a third to a half of the CPU power to paint a stupid interface. However you put it, there is no valid reason for a software left open without touching it to turn the computer into a toaster, especially since we don’t buy Russian gas anymore.
Working against ourselves
We are photographers. The fact that we need a computer to do photography is a novelty (20 years old), linked to the digital imaging technology which replaced for all sorts of reasons (good and bad) a 160 years-old technology, known and mastered. In the process, the fact that we need a computer and a software to produce images is pure and simple overhead . Forcing people who don’t understand computers to use them to perform tasks they could perfectly manage manually before is also a form of oppression, and hiding it as some technical progress is a form of psychological violence.
Software implies development, maintenance, documentation and project management. That’s several layers of overhead atop the previous. Yet the fact that the manpower in open-source projects doesn’t ask for compensation should not hinder the fact that the time spent (lost ?) on the software, its use, its development, its maintenance, is in itself a non-refundable cost.
The few examples above give an overlook of the complexification of the source code, but also of its degradation over time in terms of quality, because basic and robust features get replaced by spaghetti code , confusing and sneakily bugged. Behind this issue of legibility, the real problem is making the mid-term maintainability harder, which promises a gloomy future for the project, with the maintainer’s approval.
Since 4 years that I work full-time on Darktable, 2022 is the first year that I find myself practically unable to identify the cause of most interface bugs, because the working logic has become very obfuscated and the code incomprehensible. The number of bugs fixed is also in constant diminution, both in absolute value and in proportion of the pull requests merged, while the volume of code traffic stays roughly constant (note 1 : the following counts of lines of code include only C/C++/OpenCL and generative XML files and exclude comments 3) (note 2 : the number of opened issues is counted for the lifetime of the previous version) :
- 3.0 (December 2019, one year after 2.6)
- 1049 issues opened , 66 issues closed / 553 pull requests merged (12 %),
- 398 files changed, 66 k insertions, 22 k deletions, (net : +44 k lines),
- 3.2 (August 2020)
- 1028 issues opened , 92 issues closed / 790 pull requests merged (12 %),
- 586 files changed, 54 k insertions, 43 k deletions (net : +2 k lines),
- 3.4 (December 2020)
- 981 issues opened , 116 issues closed / 700 pull requests merged (17 %),
- 339 files changed, 46 k insertions, 23 k deletions (net : +23 k lines),
- 3.6 (June 2021)
- 759 issues opened , 290 issues closed / 954 pull requests merged (30 %),
- 433 files changed, 53 k insertions, 28 k deletions (net : +25 k lines),
- 3.8 (December 2021)
- 789 issues opened , 265 issues closed / 571 pull requests merged (46 %),
- 438 files changed, 41 k insertions, 21 k deletions (net : +20 k lines),
- 4.0 (June 2022)
- 632 issues opened , 123 issues closed / 586 pull requests merged (21 %),
- 359 files changed, 30 k insertions, 15 k deletions (net : +15 k lines),
- 4.2 (December 2022)
- 595 issues opened , 60 issues closed / 409 pull requests merged (15 %),
- 336 files changed, 14 k insertions, 25 k deletions (net : -11 k lines),
- (deletions are mostly due to the removal of the SSE2 path in pixel code, penalizing performance of typical Intel i5/i7 CPUs for the benefit of AMD Threadripper CPUs),
- 4.4 (June 2023)
- 500 issues opened , 97 issues closed / 813 pull requests merged (12 %),
- 479 files changed, 57 k insertions, 41 k deletions (net : +16 k lines),
To make things easier to compare, let’s annualize them :
- 2019 : 1049 new issues, 66 closed, 88 k changes, +44 k lines,
- 2020 : 2009 new issues, 208 closed, 166 k changes, +25 k lines,
- 2021 : 1548 new issues, 555 closed, 143 k changes, +45 k lines,
- 2022 : 1227 new issues, 183 closed, 84 k changes, +4 k lines.
It seems I’m not the only one finding the 2022’s bugs much more difficult to tackle because a lot fewer of them were fixed compared to 2021, and 2023 shows the same trend so far. The ratios of pull requests (actual work done) versus issues closed (actual problems solved) is simply ridiculous.
Between Darktable 3.0 and 4.0, the GUI code grew by 53 %, from 49 k to 75 k lines4 (discarding comments and white lines), and reached 79 k lines in 4.4. Letting the poor quality of it aside, I’m really not sure it improved the usability of the software by 53 %. In fact, I’m quite convinced of the contrary. In Ansel, I have so far reduced the GUI code to 53 k lines while removing little functionnality.
All this is just too much too fast for a bunch of hobbyists working on evenings and week-ends without structure and planning. The Darktable team works against itself by trying to bite more than it can chew, supporting too many different options, producing code which outcome depends on too many environment variables, being able to interact in too many different ways. All that to avoid making design decisions that could offend some guys by limiting features and available options. On the end-user side, this results in contextual bugs impossible to reproduce on other systems, so impossible to fix at all.
It’s simple : the work done costs more and more work, and the maintenance is not assured, as the decline of closed issues shows, because it’s simply too much. In a company, this is the time where you need to stop the bleeding before having emptied the vaults. But a team of amateurs bound to deliver no result can sustain an infinite amount of losses. Only the work created by the work is more tedious, frustrating and difficult as time goes by, and end-users are taken hostage by a gang of self-serving pricks and will pay it in terms of GUI complexity, needless CPU load, and need to relearn how to achieve basic tasks with the software at least once a year.
Actually, I’m expecting the current mass-destruction team to conveniently find less and less freetime to contribute to the project as they realize they trapped themselves in a one-way with a tractor-trailer, leaving their shit to the next ones. But the sooner they give up, the less damage they will cause.
The debauchery of options and preferences, which is the Darktable go-to strategy to (not) manage design disagreements, creates super contextual use cases where no user has the same options enabled and where it’s impossible to reproduce bugs in a different environement. And to ask users to attach the darktablerc configuration file to bug reports would not help either since that file has currently 1287 lines practically unlegible.
Weird and hardly reproduceable bugs pile up, even on System 76 computers designed specifically for Linux, where we can’t invoke drivers issues. Many inconsistent and random bugs I have witnessed while giving editing lessons are not listed on the bug tracker, and it’s rather clear that they lie somewhere in the intricacies of the if and switch case debauchery that are added at an alarming rate since 2020.
Fixing these strange and contextual bugs can only be made by simplifying the control flow of the program and therefore by limiting the number of user parameters. But the pack of geeks flapping their arms on the project won’t hear about it and, worse, the bug “fixes” generally only add more lines to deal with pathological cases individually.
In fact, Darktable suffers several issues :
- An hard core of rather mediocre developers who have a lot of free time on their hands to do random stuff, driven by the best intents in the world but oblivious of the damages they make, (mediocre people are always the more available)
- The complacency of the maintainer, who lets dirty code through to be nice,
- A critical lack of skills in pure mathematics, algorithmics, signal processing, color science and generally in abstract thinking, which are required beyond pixel processing code to simplify and factorize features,
- A despicable habit of “developing” by copy-pasting code fetched elsewhere in the project or in other FLOSS projects that may used a different pipeline architecture but without adapting it accordingly (adapting implies understanding, and that’s too much to ask…),
- A fair and square refusal to prune features to make room to new ones and keep a certain balance,
- A sampling bias, where the only users interacting with the development through Github are programmers and English-speaking. Fact is the general audience doesn’t understand what a code forge is and it’s difficult to encourage non-programmers to open a Github account to report bugs. We are talking of a users sample made of more than 44 % of programmers and of more than 35 % of university-graduated people (they are respectively 6 % and 15 % in the general population).
- A forced-march development style, without planning or dialogue, where every Github user can pollute discussions with a non-educated opinion on current work. Fact is image processing looks easy and is harmless, so much so that any person able to compute a logarithm feels competent. But the fundamental mistakes in Darkable colorimetry chain are there to remind us everday of the contrary.
- A lack of project-wise priorities regarding what features to refactor, stabilize or extend : all projects are open at the same time, even if they conflicts with each other.
- An amount of activity (emails and notifications) impossible to follow, between comments, off-topic discussions, bugs that are not, code change proposals, actual code changes that may impact your own work in progress, which means you have to be all over the place all the time ; there is a lot to read, very little to keep, discussion for the sake of discussion hinders productivity and the lack of working structure is the main cause of all that,
- Non-blocking bugs hastily hidden before we are done understanding them, instead of fixing them for real and tackling them at their root, which moves or even aggravates issues long-term without leaving traces into any kind of documentation,
- A release schedule that we keep no matter the price even when it’s not realistic, whereas nobody imposes it upon ourselves,
- Code changes that can happen anytime anywhere, meaning we work on quicksand and that we have to work as fast and as bad as the others to not be left behind the volume and frequency of the changes (commits),
- New features that degrade usability and complicate usage without solving a definite problem, that serves as recreational projects to developers untrained in design/engineering.
But the most infuriating is this obstinacy to replace simple and functional features with horrors of over-engineering destined to please deviant and marginal uses while making everybody’s life more difficult with never-ending lists of thoughtless options. The best place to hide a tree is in the middle of the forest, and many still haven’t learned it.
Mistaking agitation with activity
Any elector likes to criticize the deviance that, in politics, consists in issuing circumstancial laws, ill-written, to appease the public opinion after a special event, to show off that we act, while similar laws already exist and are not or not fully applied for lack of means. We call that agitation : this looks like action, this sounds like action, this has the cost of action, but that leads to nothing tangible or practical.
The team of amateurs without project management getting agitated over Darktable produces only future problems. In the past, Darktable was released once every year with around 1500 to 2000 commits ahead of the previous version. That’s now the volume of change achieved in 6 months. A “work” volume increasing that fast without leading to teamwork methods, including clear priorities for each release and task repartition, and without software quality control based on objective metrics (number of steps or elapsed time to achieve a particular task), it’s only dudes stepping on each other’s feet while pushing their own agenda with no care for others, nor the project, nor users.
Darktable has become the highschool computer club, where geeks have their fun. It’s globally a sum-up of all the worst stories of IT companies, with the difference that the project doesn’t make a penny, which makes it urgent to ask ourselves why we impose that upon ourselves : there are no profits to share, but everybody shares the costs. It’s a chaotic and toxic working environment which would only manufacture burn-out if the part-time amateurs were bound to deliver results and had to work full-time. Being the only full-time dude on it, I let you imagine the amount of stress and lost energy to stay up-to-date with the permanent cacophony, only to be sure to not miss the 2 % actually relevant to me in the amount of noise produced by unregulated discussions.
On the user side, we praise the effervescence of the Darktable project (yes, there is motion), without realizing that the commits runaway is not activity but agitation, and in particular technical debt which will have to be paid we-don’t-know-when by we-don’t-know-who. The beauty of a project where nobody has to take responsibility for their horseshit because nobody is accountable for nothing : it’s written in the GNU/GPL license. We can therefore screw up the work of the previous ones with total impunity.
We have the beginning of a quality control, through the integration tests, which measure the perceptual error over reference image processings, but they don’t trigger any response when we see an average error delta E of 1.3 (small) when the nature of the change should have a strictly zero delta E. If the only test passes (because we test a single SDR image over a studio shot), no question is asked on whether the theory is sound and robust. We turned the test into a discharge, as long as the metric stays under the validation threshold…
With the release of Darktable 4.0 — Geektable —, I saw on Youtube people starting to complain that this release was not very exciting. After years of dosing people with superlative releases, packed with new features we don’t have time to properly test (6-8 guys who piss 38-50 k lines every 6 months while working only evenings and week-ends, you still dreaming ?), we made them addict to the overpacked Christmas Tree to ensure that, the day we start being responsible and releasing stable versions (thus boring), that will be held against us.
The reason for this frenetic release pace is the pull requests older than 3 monthes are systematically in conflict with the master branch, given that this one is shaken every month for “generalized tests”. But the rare users who build the master branch have no idea what they need to test in particular, unless the dissected the commit history of Git, which implies to understand both the C language and the impact of the changes in practice on the software.
To limit long-lived branches, which will invariably end in conflict with the master, we found a brilliant solution : we release 2 versions each year, making forced-march development based on unfinished and barely-tested code a way of life, without ever realizing that the core problem is first the lack of planning, but also that contributors start coding before being done defining the problem to solve (when there is a real problem to solve, not just a guy who woke up like “it would be cool if…”), working in parallel on both parts without communication.
The dust doesn’t have time to settle that we are already shaking the code base again, without enforcing stabilisation phases where we only clean-up bugs (and I’m not talking of the month of feature-freeze prior to release, but of releases dedicated only to code cleaning). The bug tracker implodes in the 3 weeks following each release, because a significant part of users only uses the pre-built packages, which coincide with Christmas and Summer hollidays, where I personnaly have better things to do after the already-stressful sprint that is the month prior to release.
Since 2021, when I update my Git repository with the last changes of Darktable master, it’s always asking myself what they broke this time. We break faster than we fix, and most of the time, the fixes break something else. The only users finding Darktable stable are actually the ones making a very basic use of it, which is ironical for an app whose selling point is to be advanced.
And then, I’m being served the fact that it’s free work as if it was an excuse. But it is actually an aggravating circumstance : why do we impose such working conditions upon ourselves if it’s not even profitable ??? In addition to the fact that this free work gives me a post-release burn-out per year, it costs more and more in maintenance and the maintenance is more and more despicable to do. It’s not free work, it’s worse : it’s work that costs without paying.
Anyway, the work is provided by people who have limited time and energy. If the resource is limited, cut the bullshit : we are in the same profitability constraints as a business, minus social contributions, except our exchange money is time and it’s not refundable. Without priority management, we will get overtaken by technical debt that we will not have the resource to maintain.
What are we waiting for to be happy ?
The fact that Darktable is a steamroller in runaway mode and without a driver, which generates an increasing amount of work, is a bad smell for a 15 years-old project. Normally, a mature project slows-down because it’s complete enough to be usable and because people working on it found their cruising speed and efficient working methods.
I’m full-time on it since 2018, for a monthly income between 800 and 900 €, and it’s an understatement to say that it’s ill-payed to endure the desastrous consequences of disorganized amateurs trying to have their fun at the expense of the quality of the final product and its usability by computer Muggles. Besides, Muggles are despised too, as a principle.
If I’m crawling under a rock for a month to develop a perceptual color space, when I get out, it’s to discover the new labyrinthine system violating a bit more the view-model-controller paradigm and being told that I come too late to oppose it. If I take 3 weeks of vacation in August, it’s to discover that the maintainer bypassed (one more time) my review on a mathematical change over the aforementionned color space, which requires to sit down calmly and think, all this because… we needed to move fast ? For what emergency, exactly ?
I probably got the notification somewhere in the middle of the 2234 emails Github sent me between January and August 2022 (in 2021, it was 4044), without mentionning users who ping me everywhere, on Youtube, Reddit, Matrix, Github, Telegram, directly by emails, and previously on pixls.us (693 emails in 2022, 948 in 2021). All this for people completely out of step who don’t realize that I’m doing this all week, that photography may be their hobby but is my job, and that I would just appreciate people off my back during week-ends and hollidays. You can guess that the most annoying are not the ones financially supporting my work. People respect work only if they got billed an high price for it.
I don’t have time to be researcher, designer, on top of secretary, while doing technical baby-sitting for a team of Gaston Lagaffe who need both to be trained and to be watched because they are unable to :
1. make a development planning with a list of priorities of new features to work on, 2. provide a specicifications book of needs and issues, with a real use case, before hurrying up on their code editor and doing whatever to develop a new feature in search for a problem to solve. 3. evaluate the maintenance cost of the change before inventing the bionic bacon pump using reversed osmosis which only works on even days if Jupyter is out of phase with Saturn, 4. limit the expenses and cut down the losses when they trap themselves into design one-ways introducing regressions worse than the hypothetical benefits expected, 5. take upon themselves and delay a release if the code is obviously not ready (or I didn’t understand anything and the shareholders will ask for our heads if we release late ???).
Management (or team management) is overhead that costs some work, but the Darktable team has reached a scale where the lack of management costs actually more work, especially since none of the project founders are still in the team and the initial design blueprints need to be reverse-engineered with grep in the code everytime something needs change. That was sustainable with a reduced team where everybody knew each other, but Darktable has become an high-traffic project during Covid lock-downs and this way of working is not sustainable with current personnel.
Just go see the code ! Compare the branche darktable-2.6.x with darktable-4.2.x, file by file, and enjoy !
All I have heard so far are canned sentences like “it’s like many other opensource projects” and “there is nothing we can do about it”. People are afraid by the amount of work that a fork is (I got emails trying to convince me it was dividing productivity), without realizing the amount of resources currently wasted by the Darktable project and the permanent stress of having to base your work on an unstable code base shaken up all the time. So far, Ansel cost me less fatigue and I solved a significant number of problems among which some were reported since 2016 without signs of interest from the bloody “community”.
Besides, Ansel provides automatically-built nightly packages for Linux (.AppImage) and Windows (.exe), as to allow real generalized tests, including by people unable to build the software themselves. I asked for that back in 2019 , but apparently, geeks have better things to do, and I had to invest 70 h myself to make that happen. The operation is already a success and allowed to fix in a matter of days Windows bugs that would have taken weeks to spot in Darktable. (And Darktable grabbed 3 weeks later my AppImage build script without proper credits, but that’s a detail).
Talking about productivity, let us recall that the lighttable was rewritten almost entirely twice since 2018 (and the last version is not better nor faster) and the big change if collection filters introduced in April 2022 has overwritten another similar change (but only using 600 lines instead of 6000) introduced in February 2022 (the February version is the one in Ansel). We can’t decently utter the word “productivity” when the work of one contributor litterally erases previous work of another’s in a timeframe of one month, for simple lack of project management. It’s called stepping on each other’s feet.
So what are we doing to solve the issue ? Suffering in silence ? Living in denial ? Keeping on fixing stuff that another one will break in the next year when we will not be watching ? Keeping on making the Muggle believe, at photo forum length, that opensource is just as good as proprietary, while keeping as joker the fact that it’s free so you get no right to complain ? Isn’t that a bit too easy and dishonest, this double speech ?
Wouldn’t you like to stop making habits pass as experience and mistaking fatalism with wisdom, but rather tackle the problem at its core ? Don’t you think that you and me deserve better than software designed by amateurs whose sole talent is to have spare time and can afford to work for free since they moved to management and the kids are off to the university ?
Or I got mistaken since the beginning, and opensource is about giving over-complicated tools to geeks who don’t really need them, while trying to convince the rest of the world that open-source is not an hyper-niche for developers ?
Four years of work to get there
After 4 years of working on Darktable full-time for 70 % of minimal wage, and 2 years bearing the chronic dissatisfaction of staining my name by contributing to shit, I forked Ansel and will not go back.
In 4 years, I brought to this software something that sorely lacked : an unified workflow, based on a set of modules designed to work together, but acting each on a distinct aspect, where Darktable modules were rather a collection of disparate plugins. We are talking about :
- filmic,
- tone equalizer,
- the physically-accurate blurs module,
- both versions of the color balance,
- color calibration, including the GUI to profile with color checkers straight in darkroom and the white balancing using CIE standards,
- the negadoctor module to invert film negatives based on Kodak Cineon,
- the diffuse and sharpen module for addition and removal of blur based on thermal diffusion,
- the guided laplacian reconstruction of highlights.
I also developed more fundamental tools providing bases for the previous modules :
- a 4th order anisotropic partial differential equations solver in wavelets space for diffuse and sharpen,
- an adaptation of the predious as the guided laplacian for RGB signal reconstruction by gradients propagation,
- a perceptual color appearance model taking the Helmholtz-Kohlrausch effect into account in the saturation computation, to limit the “fluo” effect that typically comes with intense saturation settings, in color balance,
- a theoritical help in developing the exposure-invariant guided filter (EIGF), in tone equalizer,
- a linear vector equations solver by Choleski method,
- various interpolation methods of order 2, 3 and radial-based.
In the GUI, I notably did :
- refactor style declaration, removing styling from C code to map them to the CSS stylesheet, allowing to have multiple themes for the UI, including user-defined ones,
- introduce the preview mode focus-peaking and ISO 12 646 color assessment mode ,
- introduce the color vocabulary in the global color picker , allowing to name the picked color from its chromaticity coordinates, targetting color-blind photographers.
After this, I wrote dozens of documentation pages in 2 languages, published articles and dozens of hours of video on YouTube to demonstrate how to use modules, in what context and for what benefit, including quick edits using only 3 to 5 modules to process 75 to 80 % of pictures, no matter their dynamic range. In the open-source world, except perharps for projects backed-up by foundations (like Krita and Blender), this level of support and documentation simply doesn’t exist, and it’s not the developers themselves who handle this work.
Despite all this, I never had more than 240 donators, to compare with roughly 1800 unique respondents who participated in the 2020 and 2022 Darktable surveys , and who declare spending between 500 and 1000 €/an on photography.
I will not watch them destroy the usability of this software while trying to convince myself that it’s progress and there is nothing we can do about it. Instead of progress, it’s the delusional vision of progress by a bunch of fifty-something dilettantes. It’s been 2 years that I shut up patiently, trying to be nice, but looking at the degradation of base features, complexified to comply with the fads of mad programmers, I should have been despicable earlier. Playing nice solved nothing because the trend not only carried on, but accelerated, and there will be no realization before the point of no return. We can’t expect from those who created the problems to be the ones solving them.
So if I have to work for a “community” who is in mostly for the subscription-free aspect of the software, and who decided that my work is not worth minimal wage, well, I will do it under my terms and with my standards.
In terms of features, Darktable already has too much and we need to prune. It’s been 10 years that I use it and it’s already been packed with ill-design stuff. The challenge now is to present the features cleverly, and to fix annoying bugs before these idiots introduce new ones, or even fix them in their own special way : by hiding the dust under the rug. Keeping in mind that Darktable’s pipeline is 15 years old, and we can’t optimize it much more than that, given that it was already tortured a lot to avoid a full rewrite (and a full rewrite offers no benefit if we have to keep Gtk as graphical backend since it’s the primary performance bottleneck).
The solutions needed by Darktable imply to remove code and options, not to add always more. Robustness is at that price. The Darktable team does the exact opposite without learning from its mistakes.
With Ansel, I want a way to finish this work peacefully so Linux users have a reliable, consistent and performant tool for their artistic photography. Before switching to Vkdt because the current design is shows its limits.
By the way, I can no longer bare the attempt of being different for the sake of it by writing “Darktable”, proper noun, without initial capital. It’s childish, it’s neither funny or disruptive, and it makes a mess of freedesktop.org menus where the capital is anyway added to follow the standard. ↩︎
The fact that bugfixes systematically add more lines of code instead of modifying existing lines is a a concerning smell that the programming logic is bad and induces too many particular cases. Rigorous programmers always try to keep their code as generic as possible to avoid spaghetti code . ↩︎
You don’t need to trust me, the command to reproduce the stats is
git diff release-3.4.0..release-3.6.0 --shortstat -w -G'(^[^\*# /])|(^#\w)|(^\s+[^\*#/])' -- '*.c' '*.h' '*.cpp' '*.xml.in' '*.xsl' '*CMakeLists.txt' '*.cl'↩︎git checkout release-3.0.0 & cloc $(git ls-files -- 'src/views' 'src/gui' 'src/bauhaus' 'src/dtgtk' 'src/libs')↩︎
