En décembre 2019, j’ai demandé à quelqu’un de s’occuper de fournir des packages AppImages pour Darktable. Le bénéfice évident aurait été de permettre des tests anticipés, avant la sortie, de la part de personnes qui ne peuvent pas construire le code source elles-mêmes, afin de fournir espérons-le des retours précoces et aider à déboguer avant la publication. Cela n’a jamais été une priorité, ce qui signifie qu’il était acceptable d’avoir une ruée avant et après la sortie pour corriger les bugs.
Je ne plaisantais pas quand j’ai dit que Darktable était une usine de burn-out, gérée comme les pires start-ups, sauf que personne ne fera un exit et c’est en gros une perte sèche pour tout le monde impliqué. Je suis d’autant plus en colère que beaucoup d’heures-homme ont été gaspillées à encombrer l’interface utilisateur avec des cosmétiques, alors que d’avoir des builds nocturnes à usage général aurait amélioré à la fois la qualité du logiciel ainsi que le confort et la qualité de vie de ses mainteneurs. Ces objectifs n’avaient évidemment pas d’importance.
Donc, puisque on n’est jamais mieux servi que par ses propres bugs, j’ai dû le faire moi-même , et mi-décembre 2022, Ansel a obtenu des scripts de builds AppImage nocturnes que Darktable a réutilisés un mois plus tard. Avec les cohortes de gars en IT “sans compétences en mathématisation des pixels” rôdant autour de la hype de Darktable et demandant comment ils pourraient aider, bien sûr, la meilleure gestion des ressources possibles était de détourner des heures-homme de l’un des très rares gars mathématiquement dispos à disposition sur une tâche purement IT. Cela ne m’a pris qu’environ 50 heures, car avoir un script fonctionnant localement n’est vraiment pas la même chose que murmurer des scripts YAML aux oreilles de Github Action, et j’ai dû l’apprendre au fur et à mesure que je le faisais. Puisque Ansel prend 20 à 30 minutes pour se construire (ou échouer) sur les instances Github Action, votre journée de travail est une longue session de bégaiement de multi-tâches inefficace, en attendant que vos changements de script donnent un résultat à distance. Je déteste programmer, et je m’en sors pour les maths et la physique, mais ce genre de configuration de serveur banal est vraiment le pire genre de programmation qui soit, dans la mesure où ce n’est ni créatif ni cognitivement stimulant, c’est juste une manière chronophage de contourner les limitations de conception des API tierces.
Donc, finalement, Ansel était un projet logiciel semi-organisé, capable d’inclure une base d’utilisateurs plus large que simplement les geeks endurcis qui méprisent tous ceux qui ne peuvent pas mettre GCC et CMake en ordre de build, avec un gros bouton “télécharger” sur la page d’accueil qui pointerait toujours vers le build le plus récent, sans que les utilisateurs aient à déterminer lequel était le plus récent. Parce qu’un logiciel de retouche photo ne devrait pas filtrer les utilisateurs en fonction de leur culture informatique, qu’elle vienne ou non du monde Linux (ce qui n’est vraiment pas une excuse), ou il y a un mémo de la Fondation du logiciel libre que je n’ai pas reçu.
Mais le dernier problème majeur était l’absence de documentation pour les développeurs. En 2018, lorsque je commençais à contribuer à Darktable, j’avais beaucoup de mal à comprendre comment les internes étaient câblés, rien qu’en lisant le code. 7 ans plus tard, même avec toute mon expérience, je dois encore rétro-ingénier mon chemin à travers le code, utilisant autant de grep que mon intuition, car le code n’est pas modulaire, peu d’endroits utilisent des API, les commentaires manquent, et la ligne par ligne Git blame ne permet pas toujours de remonter dans l’historique des changements de conception lorsque quelqu’un a commis des (inutiles) modifications de mise en forme de code.
Ce manque de documentation pour les développeurs a conduit à de nombreuses fonctionnalités être implémentées plus d’une fois, à plusieurs endroits, par plusieurs développeurs (et parfois même par le même, au fil des ans). Au moment d’écrire ces lignes, il y a encore 4 ou 5 façons différentes, dans Ansel, d’écrire l’historique d’une image de la base de données de la bibliothèque à un fichier sidecar XMP. Certaines de ces méthodes sont rarement utilisées, donc peu testées, et les bugs peuvent passer inaperçus pendant des années, jusqu’à ce que quelqu’un signale le bug super-particulier caché dans la forêt d’options. Ensuite, pour le mainteneur en charge, c’est un stupide jeu de deviner pourquoi XMP échoue uniquement dans certaines circonstances, ce qui nécessite des fouilles archéologiques dans le code source pour découvrir qu’il n’utilise pas la méthode principale d’écriture XMP. Les XMP sont un exemple spécifique et toujours d’actualité, mais il y en avait d’autres. Vous comprenez l’idée.
J’avais noté depuis plusieurs années que les fichiers d’en-tête C (anciens) de Darktable avaient à peu près tous des docstrings Doxygen . C’est une manière très paresseuse de faire de la documentation : exécutez la commande doxygen -g <config-file> contre votre répertoire de code source, et Doxygen vous construira un site Web statique HTML de toutes les API. Ensuite, vous pouvez déposer tous les fichiers HTML dans un répertoire de serveur Web, et appeler ça votre doc de dev : la seule partie fastidieuse est d’écrire le fichier de configuration, que vous faites seulement une fois. Donc je l’ai fait : dev.ansel.photos. L’API que j’ai réécrite (comme selection.h) est documentée à mesure que j’avance. Des descriptions de haut niveau de l’architecture logicielle sont à venir.
Le gros avantage de Doxygen est qu’il produit également des graphes de dépendance des “modules” et API. Et c’est là que vous pouvez vraiment voir pourquoi j’appelle le code de Darktable des spaghettis. Voici le graphe de dépendance de accelerators.h, la partie backend pour les raccourcis clavier et MIDI :
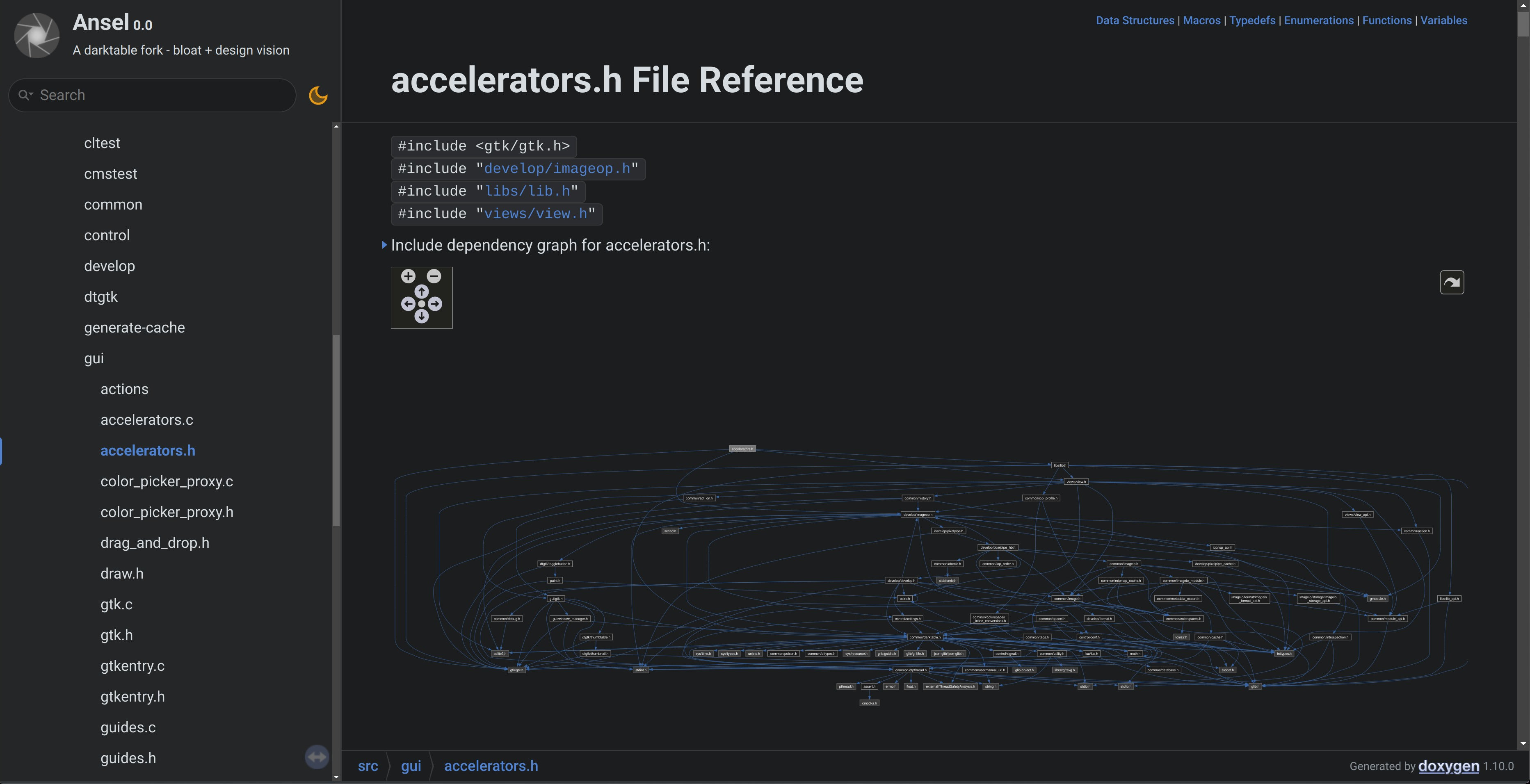
Cela montre que le backend des accélérateurs n’est absolument pas modulaire : il hérite de l’ensemble du logiciel. Donc, tout changement ailleurs peut avoir des effets imprévus là-bas, et vice versa. Ce qui est d’autant plus préoccupant puisque ce fichier a la complexité cyclomatique la plus élevée de tout le logiciel , ce qui en fait le fichier le plus difficile à maintenir (je n’ose même pas dire étendre, à ce stade, ce serait irresponsable). Mais c’est aussi complètement tordu en termes de direction des inclusions : les raccourcis sont un bloc de base qui devrait être inclus (alias hérité) dans les endroits de l’GUI qui implémenteront les raccourcis (vues chambre noire/table lumineuse, curseurs et comboboxes, modules). Au lieu de cela, le graphe (et l’en-tête du fichier #include) montre que les raccourcis incluent également (héritent) de leurs “enfants”, donc nous avons une double dépendance et c’est la pire façon possible de le faire.
C’est comme construire une maison : la maison devrait être consciente de ses murs, les murs devraient être conscients de leurs briques. Pourquoi ? Parce que la maison est faite de murs, et les murs sont faits de briques, donc chaque sous-composant détermine la nature et le comportement de l’assemblage, donc l’assemblage doit connaître ses composants immédiats. Vous ne faites pas que les briques soient conscientes de la maison, car elles ne changeront pas de nature en fonction de l’assemblée à laquelle elles appartiennent, et ce serait un design terriblement défaillant. De même qu’il s’agit d’un niveau de micro-gestion inutile de faire en sorte que la maison soit consciente des briques : une fois qu’elle est consciente de ses murs, c’est aux murs de rendre compte du comportement de leurs briques, et peut-être de distribuer l’info pertinente à la maison. Les langages orientés objet ont des moyens intégrés (et obligatoires) de gérer tout cela proprement. Mais c’est C, donc vous pouvez faire ce que bon vous semble. Cela ne signifie pas que c’est une bonne idée, cela ne signifie pas que vous devriez. Et, bien, le C n’étant pas un langage intrinsèquement orienté objet n’est pas un obstacle à l’utilisation des modèles d’objet, de l’héritage et de la modularité. C’est juste que le développeur n’aura aucune aide de la syntaxe du langage pour le faire.
Voici le même fichier après ma réécriture complète du backend des raccourcis :
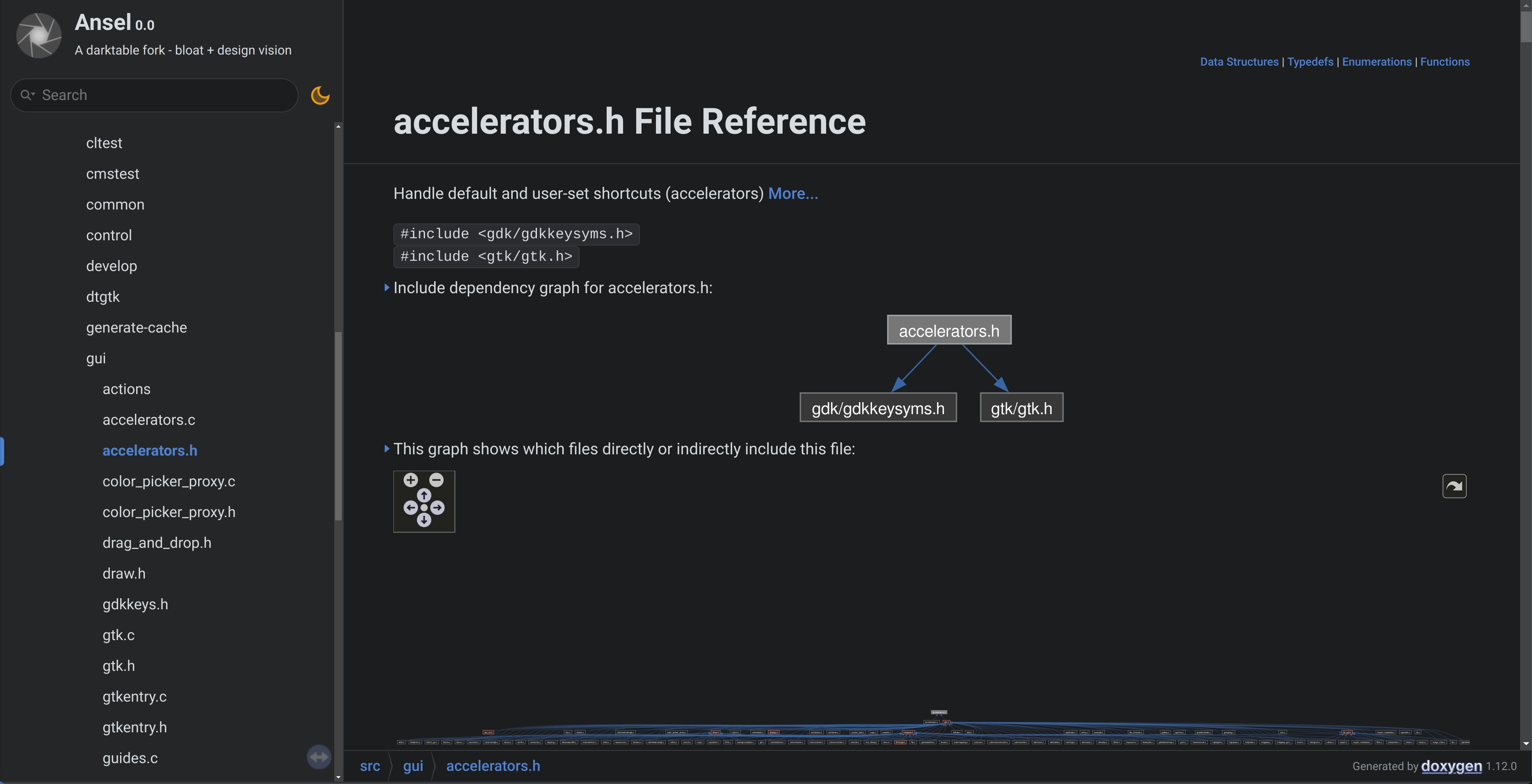
Cela montre clairement que le nouveau gestionnaire de raccourcis est un mince emballeur sur les raccourcis natifs de Gtk, il ne connaît pas le reste du logiciel et s’en moque. Nous pouvons regarder le fichier accelerators.c aussi :
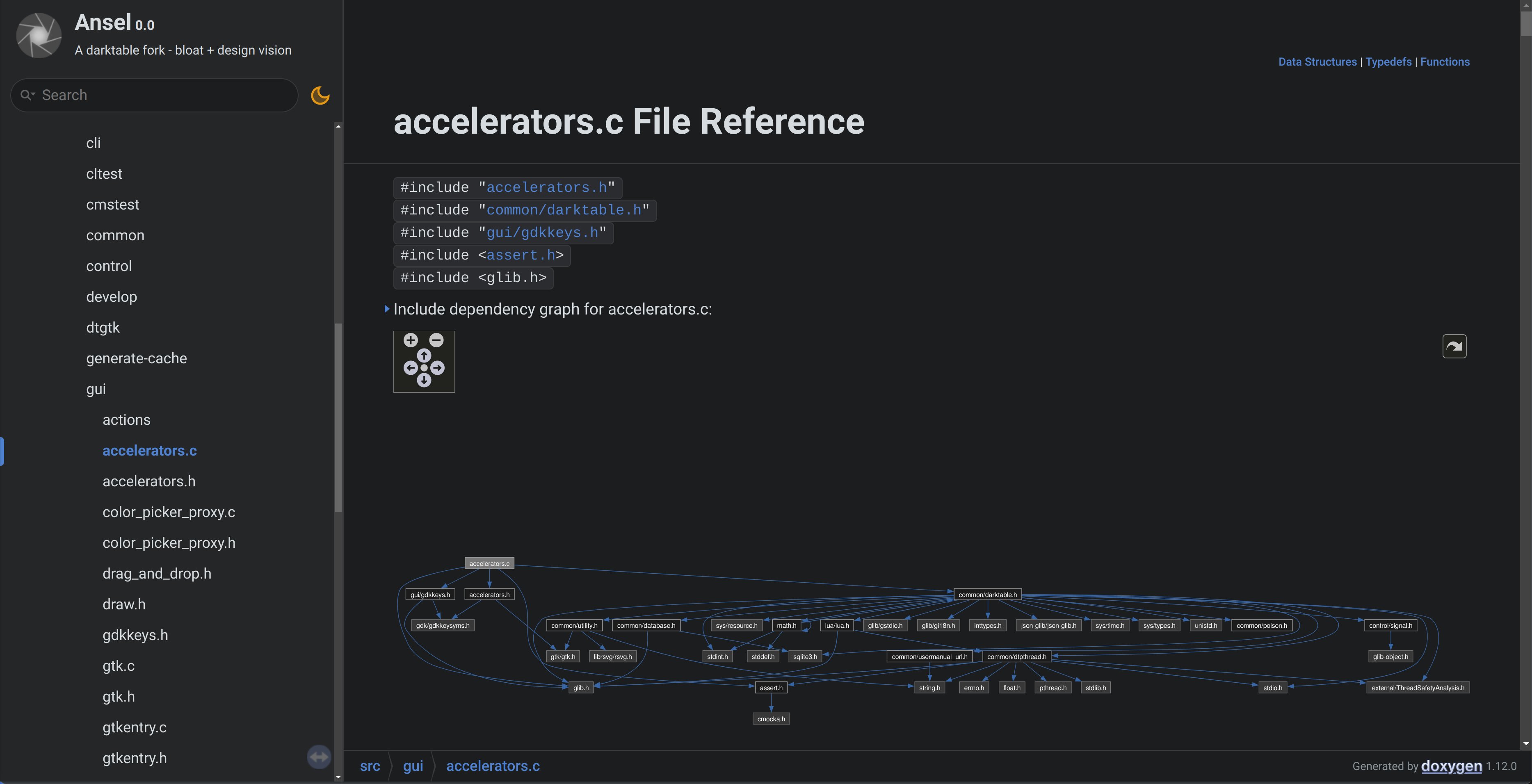
Maintenant, il y a beaucoup d’inclusions là-bas depuis darktable.h, qui est utilisé uniquement pour obtenir les aides au débogage (elles devraient être refactorisées loin de ce fichier), et inclut beaucoup de bazar inutile aussi. Quoi qu’il en soit, accelerators.c est conscient uniquement de Gtk/Gdk, ce qui signifie qu’il s’agit d’un vrai module : il est complètement isolé du reste du logiciel. Les widgets d’interface graphique qui implémentent des raccourcis déclareront leur chemin de raccourci, comme Ansel/Global/Menu/File/Import, leurs touches par défaut et une référence (pointeur) vers eux-mêmes. Les actions sans widget qui ont des raccourcis déclareront une fonction de rappel et des données d’entrée au gestionnaire de raccourcis, plutôt qu’un pointeur vers un widget.
Nous sauvegardons/restaurons les chemins et associations de clés vers/depuis le fichier keyboardrc, et c’est tout. Il n’y a pas de fenêtre pour définir des raccourcis dans le GUI à ce moment-là, mais en créer une ne fera que lister (boucler sur) les chemins connus et leurs touches associées. Lorsque le gestionnaire de raccourcis capture une combinaison de touches connue :
- pour les actions attachées au widget, il enverra un signal
activateGtk au widget concerné, et ce widget fera sa propre chose via un callback (ce qui est le même que le callback gérant les clics, donc le code est uniforme entre les clics et l’activation via clavier), - pour les actions sans widget, il appellera directement la fonction callback déclarée sur les données déclarées.
Dans les deux cas, le module accelerators communique avec le reste de l’application via une interface échangeant 4 champs de données, de manière complètement opaque. Tant que l’interface ne change pas, les changements peuvent être effectués partout : ils resteront enfermés dans leur module. Avec des compétences appropriées, cette logique aurait pu être étendue au support des appareils MIDI. Mais c’est la différence entre l’ingénierie et les preuves de concept de prototypage qui ne devraient jamais se retrouver en production.
C’est malheureusement une marque de fabrique de la manière de faire de Darktable : le code de l’GUI est incrusté partout, même dans le code SQL. À l’inverse, le code SQL se retrouve dans de nombreux endroits de l’ GUI (table lumineuse, gestion de l’historique, étiquetage des images, etc.). Les graphes de dépendance, intégrés dans Doxygen, sont un effet secondaire très sympa qui montre la profondeur du problème et rend les spaghettis très évidents, car, apparemment, les problèmes n’existent pas tant que vous ne les voyez pas vous-même.
Mais cela ne s’arrête pas là. En écrivant mon propre fichier de configuration Doxygen, j’ai obtenu une erreur : Doxygen a signalé 2 fichiers de config et était confus. Il s’avère que Darktable avait tout câblé pour la génération automatisée de documentation de développeur depuis 2010 . Pourquoi cela n’a jamais été mis en production, et réellement hébergé sur un serveur, n’est pas simplement des priorités erronées : c’est de la négligence.
Bien sûr, cela n’aide pas que le type possédant le domaine darktable.org ne soit pas le même que celui qui gère le serveur où il est réellement hébergé. Et celui qui a tous les droits de commit sur le site Web darktable.org est encore un autre. La chose la plus urgente à faire, lorsque vous êtes un projet open-source sans aucun revenu, c’est de reproduire toutes les erreurs du monde de l’entreprise, de la pression pour publier des choses à moitié finies à une fréquence irresponsable, à la dispersion des responsabilités entre les “services” qui ne communiquent pas vraiment entre eux (ou avec de grands délais).Parce qu’en logiciel (que ce soit open-source ou non), les erreurs sont faites pour être reproduites. Et comme le logiciel a pris le monde d’assaut, même dans des endroits qui n’avaient pas besoin de lui, cela en dit long sur le monde dans lequel nous vivons.
La seule chose que je ne comprends toujours pas vraiment, cependant, c’est : pourquoi l’urgence ? Pourquoi continuer à travailler aussi mal alors qu’il n’y a ni pression ni incitation financière à le faire ? L’open-source est (aurait pu être) le seul endroit où nous pourrions vraiment bien travailler et prendre le temps nécessaire pour produire de la qualité à long terme. Et même là, la myopie du capitalisme a pris le dessus.
Si seulement les utilisateurs connaissaient l’état de marasme dans lequel ce projet est tombé et comment toutes les heures-homme investies en lui contribuent activement à l’aggraver…
Note
La documentation développeur est désormais générée automatiquement et mise en ligne sur dev.ansel.photos chaque dimanche à minuit, à partir des commentaires (docstrings) présents dans le code.Translated from English by : Aurélien Pierre, ChatGPT. In case of conflict, inconsistency or error, the English version shall prevail.
