Mémoires d’un type qui a passé beaucoup trop de temps à nettoyer la merde des autres et à payer pour leurs mauvaises décisions, épisode #trop.
Le copier-coller d’historique et les styles sont des fonctionnalités centrales d’Ansel, et celles qui lui font mériter, ou non, son titre d’« application de workflow ». Mais c’est aussi l’une des choses les plus difficiles à bien faire en interne. Les utilisateurs voient une liste de retouches, mais sous le capot ces retouches dépendent de l’ordre du pipeline, des instances de modules et des masques. Si deux images ont des topologies de pipeline différentes, copier naïvement les retouches peut produire des incohérences.
Cette mise à jour rend la fusion d’historique robuste, cohérente et transparente, après un fastidieux travail de nettoyage et de simplification du code. Elle introduit aussi une gestion explicite des erreurs lorsqu’une fusion parfaite est mathématiquement impossible.
Un bref historique de la mauvaise conception
Jusqu’au début de 2019, Darktable était conçu autour d’un pipeline fixe : l’ordre des modules était décidé à la compilation par un script Python , créé par le fondateur de Darktable, Johannes Hanika, en 2011 . S’il y a bien une chose qu’on peut attendre de Jo, c’est qu’il fasse ses maths correctement, et ce script fait donc exactement ce qu’il faut dans de telles circonstances :
- laisser les programmeurs déclarer les modules,
- leur laisser définir quels modules doivent passer avant chaque module, d’une manière paresseuse et pratique qui permet de simplement dire « A doit être avant C », « B doit être avant A », « D doit être avant A », etc.,
- transformer cela en graphe orienté , qui n’est rien d’autre que l’objet mathématique collant ensemble toutes ces contraintes,
- résoudre le graphe orienté avec l’un des algorithmes de tri topologique , qui remontent aux années 1960,
- écrire l’indice numérique de chaque module dans le pipeline, et terminé.
Malheureusement, ce pipeline fixe signifiait que changer plus tard l’ordre relatif des modules casserait les anciens historiques. Ce qui était pénible, parce que certaines erreurs de conception avaient été commises sur la position de la transformation d’affichage et du module courbe de base, qui arrivaient très tôt dans le pipeline et faisaient partir les couleurs en vrille dans les situations HDR. Pour corriger cela, j’ai dû créer le module filmic comme un autre module, afin de pouvoir le placer à la fin du pipeline. Et tous les autres modules référés à l’affichage auraient dû être dupliqués dans la base de code pour pouvoir être insérés là où il fallait sans casser les anciennes retouches, y compris les miennes. Inutile de dire que le pipeline fixe avait fait son temps, et j’étais partisan de ce changement.
Avec un pipeline fixe, fusionner des historiques, c’est-à-dire copier-coller des historiques entre images ou appliquer des styles à des images, ce qui revient au même, était facile : il suffisait de remplacer les paramètres de modules et les masques en 1:1. Même avec les modules multi-instances, introduits vers 2014, ce n’était pas si terrible parce que toutes les instances devaient rester consécutives et étaient numérotées relativement les unes aux autres. Donc, après avoir créé les instances manquantes à une position prévisible et invariante, en ordre séquentiel après l’instance de base, on remplaçait toujours paramètres de modules et masques en 1:1.
Mais la fonctionnalité pourtant indispensable de réordonnancement du pipeline, à l’exécution et par les utilisateurs, arrivée avec Darktable 3.0, a été faite de la pire manière possible. Le développeur qui l’a implémentée gérait l’indexation avec des tableaux de priorités en virgule flottante, ce qui n’est pas la bonne structure de données pour ce problème. En plus, le code de gestion d’historique n’a pas été refactoré ni simplifié avant d’être étendu, mais bricolé sur place avec des changements minimaux, ce qui l’a rendu vraiment complexe et opaque. Pascal Obry, qui avait accepté ce changement en 2019, a dû réécrire tout le backend de réordonnancement du pipeline en 2020, en utilisant la structure de données adaptée à la tâche, des listes chaînées , parce que la précédente était fragile et impossible à maintenir.
Mais fusionner des pipelines, qui peuvent avoir des nombres de modules différents, ordonnés à des endroits imprévisibles et non invariants, ne peut se faire autrement qu’avec un tri topologique à l’exécution, parce que ce n’est plus seulement un problème d’historiques, c’est-à-dire d’instantanés des paramètres des modules, mais un problème double qui inclut les historiques et la topologie du pipeline. En d’autres termes : il faut résoudre où insérer les instances de modules qui existent dans le pipeline source mais pas dans la destination. Pourtant, le script Python qui faisait cela à la compilation a été supprimé en 2019, et la fonctionnalité n’a jamais été portée en C.
Donc, la manière dont Darktable gère encore aujourd’hui la fusion des pipelines repose sur des heuristiques bricolées à partir du paradigme du pipeline fixe, et globalement cassées, sauf dans les cas gentils qui correspondent aux conditions des pipelines de 2018 et d’avant :
- si vos pipelines source et destination ont le même nombre de modules ordonnés de la même manière, tout va bien,
- si votre pipeline source possède des instances de modules supplémentaires par rapport à la destination, mais que ces instances se trouvent toutes juste après l’instance de base, tout va encore bien,
- mais… si vous avez des instances supplémentaires, côté source ou destination, et qu’elles ont été déplacées dans le pipeline, alors le comportement n’est pas spécifié, pas prévisible, et cela fait plus de 5 ans que je copie-colle des historiques en retenant mon souffle,
- de plus, il existe une liste de modules « clôture » qui nécessitent un ordre relatif précis, par exemple calibration des couleurs doit impérativement passer après profil de couleur d’entrée, mais aucun moyen de l’imposer, aucun moyen de le corriger lorsque de mauvais ordres apparaissent, seulement des messages d’erreur silencieux dans la console.
Ajoutez à cela les masques raster, pour lesquels le module réutilisant un masque raster doit impérativement se situer plus tard dans le pipeline que le module qui le produit, et où, au passage, vous pouvez vouloir copier le producteur avec le consommateur, ou au moins recevoir un avertissement si vous ne le faites pas… et vous obtenez la recette de la folie.
En pratique, vous devez ouvrir chaque image et vérifier la pile de modules dans la chambre noire, ce qui est atrocement lent.
Parce que Darktable se définit par une mauvaise gestion des priorités, beaucoup de cosmétique a reçu beaucoup de travail : il vous laissera retoucher vos images avec des manettes PlayStation, il s’apprête à recevoir des fonctions de masquage par apprentissage profond, mais il arrive encore à foirer les bases fondamentales, sans aucune amélioration en 6 ans malgré l’activité apparente du projet.
Le problème (TL;DR)
Auparavant, le collage d’historique essayait de fusionner les modules un par un au fil de l’eau. Cela fonctionnait dans les cas simples mais devenait peu fiable lorsque :
- l’image source avait un ordre de pipeline différent,
- il y avait plusieurs instances d’un même module,
- ou des masques et des modes de fusion étaient impliqués.
Comme la fusion ne résolvait pas le problème d’ordre dans sa globalité, le résultat pouvait dépendre de beaucoup de choses. Dans certains cas, le pipeline final pouvait se retrouver incohérent avec la pile d’historique.
La correction
J’ai implémenté un algorithme de tri topologique en C. Ou plus exactement, ChatGPT l’a fait et je l’ai vérifié, davantage là-dessous. 304 lignes de code, ce qui est très peu pour du C.
Nous traitons désormais l’ordre du pipeline comme un ensemble de contraintes à résoudre globalement, et non module par module. En pratique, cela signifie :
- Nous résolvons d’abord la topologie du pipeline, puis l’historique de développement, c’est-à-dire les paramètres des modules. Deux étapes nettes qui rendent la gestion des erreurs possible.
- La fusion calcule un ordre de pipeline unique et valide qui satisfait à la fois la source et la destination lorsque c’est possible, quel que soit le nombre d’instances de modules et leur ordre.
- Si les contraintes sont incompatibles, Ansel peut expliquer le conflit et demander quel ordre préserver.
- Si un conflit est insoluble, Ansel le signale clairement au lieu de produire un pipeline cassé ou instable, et vous donne des options pour le corriger.
- Des contraintes sont aussi posées sur les modules qui utilisent et consomment des masques raster, et un avertissement est émis si un utilisateur de masque raster est copié sans son producteur.
- Des contraintes codées en dur sont posées sur les modules qui nécessitent qu’un autre les précède, pour des raisons techniques, par exemple reconstruction des hautes lumières avant dématriçage, profil de couleur d’entrée avant calibration des couleurs, etc. Ces contraintes sont traitées comme les autres et résolues ensemble, sans cas particulier.
Concernant la seconde partie, l’historique proprement dit, il faut clarifier une chose. L’historique de Darktable et d’Ansel ressemble beaucoup à une liste d’annulation/rétablissement d’instantanés des paramètres des modules : chaque entrée d’historique est liée à un module et représente son état interne de paramètres et de masques. Lorsqu’on charge l’historique dans les nœuds du pipeline, les nœuds étant les filtres de pixels attachés aux « modules » visibles dans l’interface, on lit l’historique du bas vers le haut et on copie chaque entrée, chaque instantané, dans les modules, ce qui signifie que les instantanés plus récents écrasent toujours les plus anciens.
Autrement dit, l’historique est ordonné par le moment où l’utilisateur a modifié les choses, encore une fois pensez à une liste d’annulation/rétablissement d’instantanés, et non par l’ordre des nœuds du pipeline. Mais là où cela devient confus, c’est que les entrées d’historique stockent aussi la position d’un module dans le pipeline, ce qui signifie que le réordonnancement des modules laisse des traces dans l’historique. Cela a embrouillé les développeurs de Darktable, et encore davantage les utilisateurs. Alors séparons conceptuellement les deux, dans nos têtes comme dans le logiciel.
La topologie, c’est-à-dire l’ordre des nœuds du pipeline, est indépendante de l’historique. Contrairement à Darktable, qui gère tout au travers des entrées d’historique, y compris l’ordre du pipeline, ce qui est activement nuisible à la compréhension comme à la complexité du code, les deux allant de toute façon ensemble, nous résolvons le pipeline comme une collection autonome de nœuds, c’est-à-dire de modules, puis nous rematchons les nœuds avec leur dernier état dans l’historique. Il m’a fallu quelques années pour voir au travers de toute l’obfuscation écrasante enfouie dans ce logiciel, enterrée dans du code copié-collé, et comprendre enfin : une fois abstrait, le problème est plutôt simple.
Donc, une fois la topologie résolue, il nous reste 3 modes de fusion d’historique :
- replace : l’historique source remplace toute la destination, des modules obligatoires comme le dématriçage pour les images RAW peuvent quand même être rajoutés par-dessus, ce qui rend le copier-coller sûr entre JPEG et RAW. Ce mode n’implique aucun tri topologique, c’est une copie directe de l’historique et de l’ordre du pipeline.
- append : l’historique source est ajouté au-dessus de la destination, de sorte que les entrées d’historique visant les mêmes modules dans la source et la destination sont écrasées par la source,
- appstart : l’historique source est placé en dessous de la destination, de sorte que les entrées d’historique visant les mêmes modules dans la source et la destination sont écrasées par la destination.
L’ordre du pipeline résolu par tri topologique est mis à jour dans les dernières entrées d’historique, à la fois en mode append et appstart, ce qui signifie qu’un retour en arrière dans l’historique annule aussi le tri topologique. Les historiques ne sont volontairement pas compressés lors de la fusion, afin que les utilisateurs conservent la possibilité d’annuler la fusion soit avec les fonctions d’annulation/rétablissement, soit en revenant en arrière dans le panneau d’historique, dans la chambre noire, avant le point de fusion.
En bref : le collage d’historique est désormais déterministe, sûr et non destructif, même pour des retouches complexes.
Interface et gestion des erreurs
La beauté de la nouvelle solution, c’est que vous n’avez pas besoin d’ouvrir la chambre noire pour voir le chaos créé par un copier-coller bancal ; vous pouvez le vérifier dans la table lumineuse avant que vos retouches ne soient abîmées. En plus, lorsque le solveur ne parvient pas à trouver une solution, ce qui arrive avec des contraintes incompatibles, par exemple A doit précéder B mais B doit précéder A, ou avec des cycles, davantage ci-dessous, il est capable de dire ce qui échoue, de le signaler, puis soit de demander une intervention de l’utilisateur pour corriger, soit de revenir au chemin le plus raisonnable. Laissez-moi vous montrer :
Cycles triviaux
Exposition 1 est avant Exposition dans l’historique source, mais après dans l’historique destination. L’ensemble des contraintes se retrouve avec Exposition → Exposition 1 → Exposition, ce qui est infaisable. Voici ce qui se passe dans Ansel :
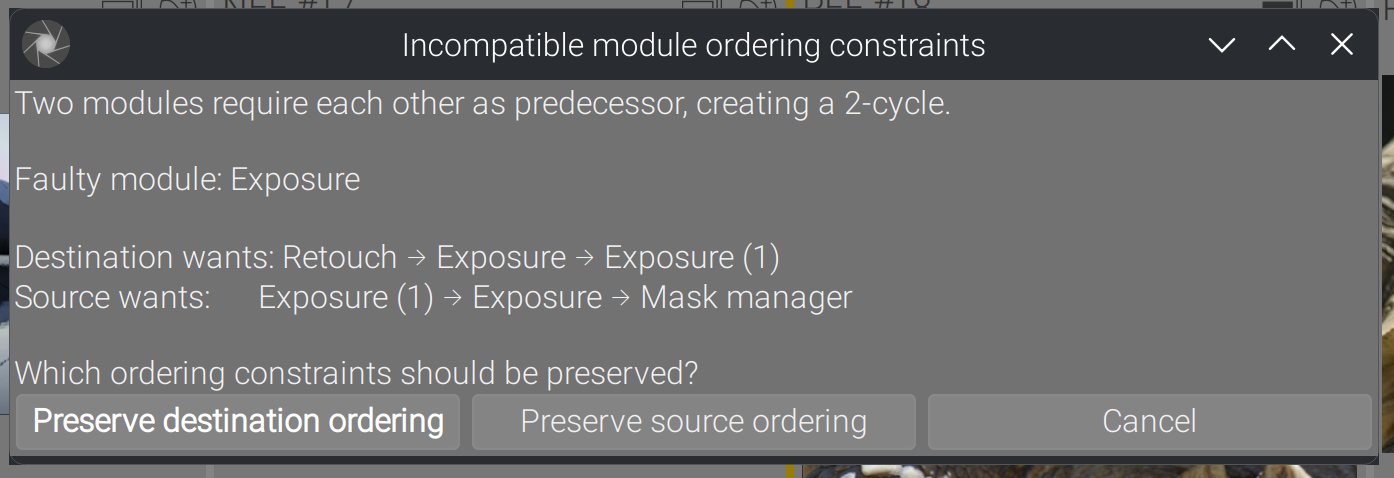
Ces cycles triviaux impliquant des voisins immédiats sont détectés avant la résolution, donc ils n’interrompent pas le flux de contrôle.
Cycles non triviaux
Ces cycles non triviaux impliquent plusieurs modules et ne peuvent pas être détectés avant d’essayer de résoudre le graphe orienté. Lorsque cela arrive :
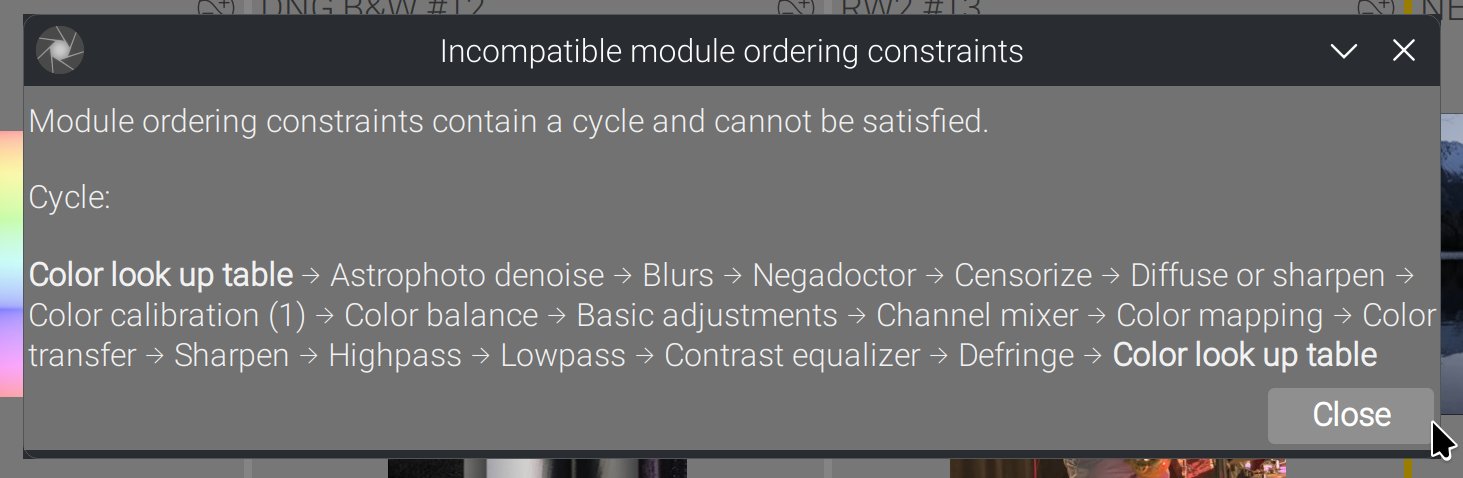
Dans ce cas, il n’y a rien à faire : nous réessaierons automatiquement en utilisant l’ordre de la destination, puisque cela se produit typiquement lorsqu’on essaie d’importer l’ordre source dans la destination.
Masques raster oubliés
Tout module utilisant un masque raster devrait être copié avec le module qui produit ce masque, sauf si vous prévoyez de résoudre cela vous-même plus tard. Au cas où ce serait une erreur, si vous essayez quand même :
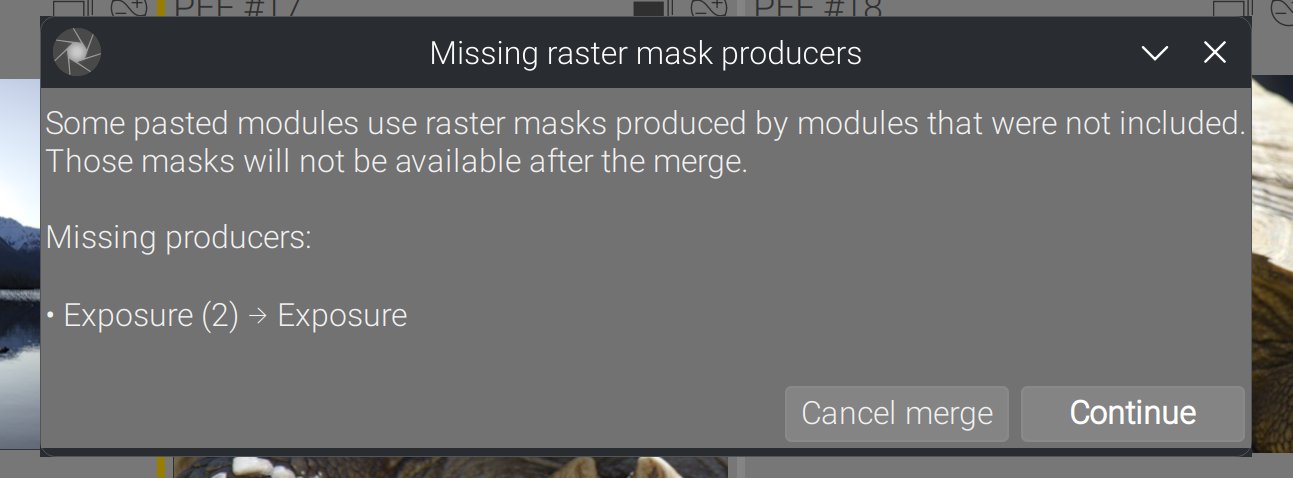
Vous avez alors la possibilité d’annuler immédiatement la fusion si ce n’était pas ce que vous vouliez.
L’interface du rapport de fusion (nouveau)
Principes
La boîte de dialogue du rapport est conçue pour répondre à une question simple de l’utilisateur : « qu’est-il exactement arrivé à mon pipeline ? »
Elle affiche quatre pipelines côte à côte :
- Original (le pipeline de destination avant la fusion),
- Source (l’image depuis laquelle vous avez copié),
- Remplacement (là où les retouches source ont remplacé celles de la destination),
- Destination (le pipeline final après la fusion).
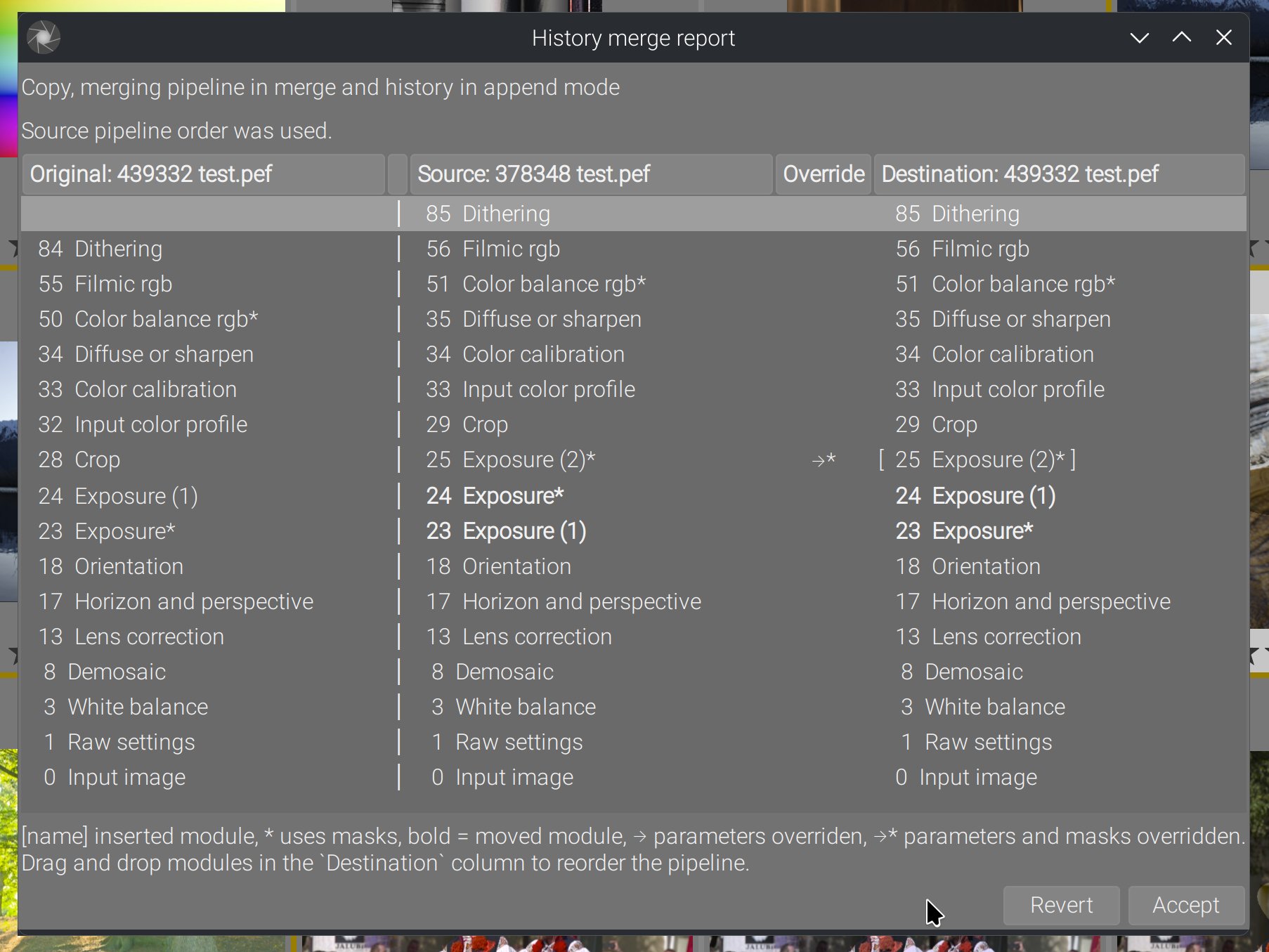
Chaque colonne liste les instances de modules actives, dans l’ordre de l’interface. Cette vue inclut des marqueurs supplémentaires :
- Des crochets
[nom]indiquent les modules nouvellement insérés. - Un astérisque
*indique les modules qui utilisent des masques. - Un libellé en gras indique les modules dont la position relative a changé entre la source et la destination.
- Des flèches de remplacement montrent où l’historique source a effectivement remplacé les retouches de destination, avec
→*lorsque les masques ont aussi été écrasés.
Bonus
La colonne destination peut être réordonnée par glisser-déposer, ce qui signifie que si le résultat du tri topologique ne vous convient pas, vous pouvez le corriger vous-même immédiatement, avant même qu’il ne soit enregistré dans votre base de données et votre XMP, et sans avoir à ouvrir la chambre noire. Cela vous permet d’ajuster manuellement le pipeline final avant de l’accepter, ou de tout annuler sans réécrire l’historique.
Lorsque vous réordonnez :
- l’ordre du pipeline est mis à jour immédiatement,
- les entrées d’historique restent cohérentes avec le nouvel ordre,
- et la vue de rapport met à jour en conséquence ses libellés et ses marqueurs « déplacé ».
C’est conçu comme une soupape de sécurité : même si l’ordre calculé est valide, vous avez toujours un moyen simple de l’ajuster.
Pourquoi c’est important
Cela améliore directement les workflows impliquant des retouches par lots avec des pipelines complexes :
- le copier-coller de retouches entre images,
- le mélange de sources et destinations RAW et JPEG,
- et les retouches lourdes à base de multiples instances ou de masques.
L’objectif est de rendre le collage d’historique prévisible, même lorsque les pipelines sous-jacents diffèrent. Cette fiabilité est particulièrement importante pour les retouches avancées où de petites différences d’ordre peuvent changer le résultat.
Ce changement n’ajoute pas de fonctionnalité tape-à-l’œil : il rend simplement l’une des fonctions les plus utilisées digne de confiance. Les fusions d’historiques se comportent maintenant comme les utilisateurs l’attendent : des résultats cohérents, des rapports clairs et des replis sûrs lorsque les contraintes entrent en conflit.
Et je ne comprends toujours pas pourquoi, 6 ans plus tard, les gars du It Works For Me® qui font s’écraser Darktable au ralenti n’ont pas envisagé d’améliorer une fonctionnalité aussi basique et pourtant critique. Si ça ne hurle pas « mauvaises priorités », je ne sais pas ce qui le fera.
Ce qui l’a rendu possible
Je veux souligner ici que toute cette réécriture n’a été possible que parce que j’avais d’abord presque entièrement réécrit le backend de gestion de l’historique dans Ansel, puisqu’il était en ruine :
- Il y avait des fonctions dupliquées partout, exécutant la même opération de multiples fois mais cachées dans des fonctions appelées et appelantes réparties dans tout le logiciel, certaines déclenchant des E/S sur le système de fichiers, écriture de XMP, sans raison, l’une d’elles réécrivant l’historique à chaque ouverture de la chambre noire, ce qui cassait l’horodatage du dernier changement,
- Il y avait plusieurs verrous de threads entrelacés qui rendaient pratiquement tout changement impossible sans provoquer de deadlocks,
- Il y avait du code de récupération d’historique SQLite3 enchevêtré dans le code C, beaucoup de requêtes SQL dupliquées, aucune thread-safe, puisque SQLite3 lui-même n’est pas thread-safe, alors j’ai enterré tout le SQL dans une interface C gérant la sûreté des threads de manière centralisée, et maintenant tout le code C récupère les informations d’historique depuis la base de données de la bibliothèque via une API unique, ce qui signifie que tout ce qui lit l’historique le lira de la même manière partout dans l’application,
- Certaines parties de la lecture, de l’initialisation et de la fusion d’historique étaient faites en SQL, en exploitant des
JOIN, ce qui a du sens, mais…, et d’autres en C, puisque les vérifications de sûreté des modules et l’initialisation des préréglages sont évidemment en C. Cela menait à des absurdités comme réindexer manuellement les entrées d’historique en C avant leur enregistrement en base entre des écritures transitoires, parce que SQLite3 ne garantit pas que les entrées d’historique seront sauvegardées dans le même ordre que celui dans lequel elles lui ont été passées… c’est précisément à cela que servent les clés primaires. J’ai donc tout réécrit en C, ce qui est peut-être un peu plus lent mais garantit la cohérence des données : les historiques sont traités exactement de la même manière qu’on les charge pour les fusionner, qu’on ouvre la chambre noire ou qu’on exporte une image. S’il y a un bug quelque part, il sera partout et on le trouvera plus vite, et en plus on le corrigera à un seul endroit. - Le code de gestion d’historique était aussi entremêlé avec le code d’interface graphique, alors qu’il peut également fonctionner depuis
ansel-cli, donc sans interface, ce qui entraînait de nombreuses heuristiques vérifiant dans beaucoup d’endroits si une interface graphique était présente ou non.
Donc, une fois tout ce travail de nettoyage accompli, j’ai commencé à voir la structure de ce qui avait réellement été fait et de ce qu’il fallait faire. À partir de là, une simplification en a entraîné une autre, jusqu’à ce que ChatGPT 5.2 Codex fasse le reste. Il y a encore 2 semaines, tout cela se faisait entièrement à la main et cela m’a rendu fou bien des fois. Ce qui tenait ces murs, c’était vraiment juste de la peinture, de la peinture qui s’écaille, et tenter de nettoyer le tout détruisait beaucoup de choses parce que rien dans ce logiciel n’était modulaire, c’est-à-dire encapsulé. Ce que vous changez à un endroit a des conséquences inattendues ailleurs, raison pour laquelle nous avons l’encapsulation, la modularité et les design patterns, puisque le langage C n’a pas été conçu pour des applications de bureau complexes comme celle-ci, et qu’il faut une vraie discipline de développeur pour qu’il ne devienne pas le cauchemar qu’il est.
Tout cela est entièrement vibecodé
Le nettoyage de l’historique traînait donc depuis 2023, en gérant au passage un burn-out et une dépression induite par le logiciel. C’est une qualité de vie de merde, vous n’avez pas idée. Ceux qui pensent que j’exagère ne savent pas ce que cela implique de pelleter les excréments cérébraux des autres pendant plus de 3 ans. Parce que j’ai connu une époque où tout cela était, sinon meilleur, au moins moins compliqué et plus gérable. Puis la folie du COVID-19 a frappé, et des idiots se sont retrouvés avec trop de temps libre, qu’ils ont utilisé pour détruire quelque chose qui fonctionnait à peu près.
Et puis j’ai découvert ChatGPT 5.2 Codex il y a 2 semaines, et je l’ai installé dans l’éditeur VS Code. Il m’a donc fallu 3 jours de travail pour faire tout ce que je présente ici. Sans ChatGPT, cela aurait été 3 bonnes semaines, plus l’interminable bidouillage avec les détails de GTK. Parlons donc de l’expérience.
Je ne suis pas d’accord avec ceux qui essaient de nous faire croire que l’IA générative n’est qu’un outil. Un outil ne fonctionne que dans ma main. Pas quand je dors. J’ai fait travailler ChatGPT pour moi pendant que je cuisinais le dîner, oui, c’est à ce point lent. On ne communique pas avec un outil, on l’utilise du mieux possible. En cas d’échec, certains blâment l’outil, mais on sait tous ce que cela signifie. Le problème, c’est que ChatGPT n’a ni boutons ni curseurs, il interprète ce qu’on lui dit, pas forcément comme on l’entend. Et puis un outil ne prend pas d’initiative. Or ChatGPT a clairement une opinion sur la manière dont le code devrait être écrit, et il faut parfois se battre contre elle.
L’IA générative est un stagiaire. Un stagiaire n’a pas d’expérience et ne connaît que ce qu’on lui enseigne à l’école. Un stagiaire peut apporter des idées fraîches qui bousculent vos habitudes, et tout autant des suggestions délirantes qui ne sont absolument pas pertinentes dans votre contexte, parfois même pas réalisables. Mais un stagiaire doit travailler sous surveillance étroite et recevoir des instructions claires, sans ambiguïté. ChatGPT est bien plus un stagiaire qu’un outil.
ChatGPT fait beaucoup d’erreurs, et elles sont sournoises parce qu’elles sont enterrées au milieu de contenu parfaitement valide. Il a quelques obsessions bizarres, comme vérifier que chaque pointeur n’est pas NULL alors qu’on sait déjà qu’il ne peut pas l’être. Il faut donc vraiment le surveiller. Cela dit, relire et corriger ses erreurs reste plus rapide que d’écrire moi-même tout le code, sans même parler du fait que mon premier syndrome carpien remonte à 10 ans, donc c’est toujours autant de texte à ne pas taper. En plus, il se trompe sur la logique, mais pas sur les fautes de frappe, ou en tout cas beaucoup moins que moi.
Mais là où ChatGPT Codex brille, c’est sur 2 choses.
D’abord, le fastidieux jeu qui consiste à faire des grep sur les fonctions à travers toute la base de code pour reconstituer le cycle de vie des données et vérifier tous les sites d’appel afin de construire un modèle mental de ce qui se passe. Cela prend un temps fou, c’est très exigeant cognitivement, surtout dans une base de code aussi pourrie. ChatGPT fait des merveilles pour parcourir des dizaines de fichiers, extraire des motifs, trouver ce qui pourrait être factorisé et suivre des séquences d’exécution. Soyons très clairs : dans une base de code correctement maintenue, cela ne devrait pas être nécessaire, parce que le code serait encapsulé dans des modules, isolé du reste. Mais ChatGPT a beaucoup aidé à rendre les choses plus modulaires.
Ensuite, tout ce qui touche à GTK et GLib. C’est mal documenté sur le web, et beaucoup de motifs idiomatiques d’interaction ne sont connus que des développeurs GTK. ChatGPT a manifestement ingéré énormément de code open source et peut produire du code d’interface générique bien meilleur que ce que je pourrais, ou voudrais, écrire. Bref, avant ChatGPT, cela se transformait en séances fastidieuses de recherche Google, et je ne trouve plus d’information technique pertinente sur Google depuis 2020 environ, depuis qu’ils ont changé leurs algorithmes pour surinterpréter agressivement tout ce qu’on cherche. Or moi, je travaille pour résoudre des problèmes, et toutes les fonctions de plomberie d’interface qui initialisent des widgets et leurs propriétés dans un style déclaratif ne méritent pas mon intelligence, il s’agit juste d’essayer de ne pas introduire de fautes de frappe.
Mais pour vous donner une meilleure idée, voici le genre de prompts que j’ai dû lui donner pour construire ce que je viens de présenter :
maintenant, dans _hm_try_merge_iop_order_topologically(), construis tôt dans la fonction une GHashtable de tous les IDs de modules liés à mod_list, puis à dev_src->iop, puis à dev_dest->iop. Cela servira plus tard à calculer des intersections d’ensembles. ne modifie pas dev_dest->iop_order_list. Pour chaque élément de la liste triée, l’élément étant un ID de nœud lié à un op de module et à multi_name :
- détermine si une instance de module correspondante existe dans dev_dest->iop, sinon crée-la. Comme dev_dest->iop est déjà initialisé et assaini en amont, on peut supposer en toute sécurité que chaque module non trouvé doit être inséré comme une nouvelle instance. Si l’ID de l’instance de module est trouvé dans la mod_list d’entrée, tout le contenu du module, paramètres, blendop, etc., doit être copié de l’instance source vers l’instance destination. Fais attention aux copies profondes nécessaires.
- écrase toutes les valeurs module->iop_order avec le nouvel indice que nous venons de trouver en résolvant
- reconstruis dev_dest->iop_order_list à partir de zéro et mets à jour module->multi_priority en conséquence
maintenant, dans dt_history_merge_module_list_into_image_advanced, l’historique temporaire doit être construit comme suit :
- désimplémente pour l’instant le chemin force_new_modules, nous y reviendrons plus tard autrement,
- construis un historique temporaire ainsi : pour chaque module de mod_list :
- récupère l’entrée d’historique associée depuis dev_src->history, ce sera la dernière correspondant à ce module dans la pile d’historique,
- récupère les informations d’ordre dans le pipeline, iop_order, instance, multi_priority, depuis le module correspondant dans dev_dest->iop
- mets à jour l’entrée d’historique existante de dev_src->history avec les informations d’ordre du pipeline, puisqu’elles ont pu changer après le tri topologique, à partir de l’entrée d’historique d’origine,
- ajoute cette entrée d’historique à l’historique temporaire
- concatène l’historique temporaire avec dev_dest->history, au début ou à la fin selon le mode append ou appstart.
Essaie d’utiliser autant que possible les méthodes de history.c et dev_history.c pour la gestion de l’historique depuis et vers les modules. Étends celles qui existent déjà si tu n’as besoin que de changements mineurs.
Non, annule ça. Ce n’est pas acceptable de supprimer en général les entrées d’historique au-delà de history_end. Tout ce qu’il y a dans dev->history doit partir dans la base de données. Ce n’est d’ailleurs pas un problème puisque history_end est lui aussi enregistré en base. Le vrai problème, c’est que des entrées d’historique aléatoires sont ajoutées lors de la relecture depuis la base. Tout ce qui se passait avant l’écriture de l’historique, donc en C, était correct. Trouve pourquoi nous obtenons des entrées d’historique supplémentaires lors de la lecture depuis la base, par rapport à ce que nous avons au moment de l’écriture juste avant.
à la fin de dt_history_merge dans history_merge.c, je veux que tu affiches une fenêtre popup de rapport. Un libellé de texte devra d’abord dire « Copy, merging pipeline in {MERGE_MODE} and history in {STRATEGY} mode », où {MERGE_MODE} dépend de merge_iop_order, merge ou destination, et {STRATEGY} dépend de strategy. Ensuite je veux un GtkTreeView en mode liste, avec 3 colonnes :
- la source de la copie, avec l’ID de l’image et son nom de fichier, pas le chemin complet,
- le remplacement,
- la destination de la copie, avec l’ID de l’image et son nom de fichier.
Dans les colonnes 1 et 3, chaque ligne montrera les instances de modules, en commençant par leur ordre dans le pipeline, module->name et module->multi_name. Seuls les modules activés seront affichés. La colonne 2 dessinera une flèche entre les instances source et destination lorsque l’historique source écrase l’historique destination. Cela se fait en vérifiant, dans l’historique de destination, si la dernière entrée visant ce module correspond à l’historique destination ou source. Si elle correspond aux deux, n’affiche rien puisque ce n’est pas un écrasement. Les nœuds du pipeline seront affichés en ordre inverse pour correspondre à l’ordre de l’interface, puisque c’est une sorte de pile de calques. Ils devraient tous deux être alignés par le bas pour que les premières étapes aient une chance d’être sur la même ligne jusqu’à ce que la topologie diverge entre les deux pipelines
Une chose que j’ai découverte, c’est qu’on peut tout à fait être trop spécifique avec ChatGPT et le mener dans une impasse. Quand cela arrive, le mieux à faire est de reprendre la main manuellement.
Le coût énergétique de ce machin est insupportable, mais disons que, réparti sur les quelque 900 types qui ont mis une étoile à Ansel sur GitHub, je n’ai pas les statistiques de téléchargement, c’est pour le bien commun. C’est simplement une manière plus efficace d’économiser mon jus de cerveau pour réfléchir à ce qu’il faut faire, conception et architecture, plutôt qu’à comment le faire. Ce n’est probablement pas comme ça que les gamins vibecodent de nos jours, cela dit.
Prochaine étape : les styles.
Translated from English by : Aurélien Pierre, ChatGPT. In case of conflict, inconsistency or error, the English version shall prevail.

Comment l’utiliser
Il y aura un historique source, celui que vous copiez, et un historique destination, celui dans lequel vous collez. Il en ira de même avec les styles lorsqu’ils seront réimplémentés ; l’historique source sera défini par le style au lieu d’une autre image, et le reste sera identique.
Dans le menu global Édition → Mode de collage d’historique, vous pouvez choisir entre append, appstart ou replace. Le réglage est global à toute l’application. Il détermine quel historique, source ou destination, prend le dessus en écrasant les modules communs.
Dans Édition → Mode de collage des nœuds, vous pouvez activer ou désactiver Copier l’ordre des modules. Si c’est désactivé, l’ordre du pipeline de destination est conservé tel quel. Si c’est activé, nous faisons de notre mieux pour importer dans la destination l’ordre du pipeline source.
Comme auparavant, dans le menu Édition, vous disposez des options pour tout copier-coller, ou seulement les modules sélectionnés, via la fenêtre modale. Des raccourcis globaux sont disponibles et modifiables par l’utilisateur. Notez que le copier-coller d’historiques est explicitement interdit dans la vue chambre noire, même depuis la pellicule, parce qu’il est ambigu de déterminer si vous voulez copier entre miniatures, de la miniature vers l’image principale ou l’inverse. Dans la table lumineuse, vous sélectionnez la source, vous copiez, vous sélectionnez la destination, vous collez, et tout est clair.
Maintenant, il y a une hypothèse importante à garder en tête : les modules qui portent le même nom d’instance, numéro d’instance par défaut ou nom défini par l’utilisateur, sont considérés comme la même entité dans les historiques source et destination. Ainsi, chaque module Exposition (ciel) sera fusionné avec chaque autre module Exposition (ciel), la casse étant significative, et il ne devrait y avoir qu’une seule instance Exposition (ciel) dans les historiques source et destination. Auparavant, le code utilisait les numéros d’instance, ce qui est plus fragile parce qu’ils sont imposés par le logiciel et incrémentés dans l’ordre de création, ce qui n’a aucun sens pour les utilisateurs.