Qu’est-ce qui se passe quand une bande de photographes amateurs, devenus développeurs amateurs, rejoints par une poignée de développeurs back-end qui développent de la librairie pour développeurs, se décide à travailler sans méthode ni structure sur un logiciel métier pour utilisateur final dont le cœur de compétence (colorimétrie et psychophysique) se situe quelque part entre un BTS photo et un BAC+5 en sciences appliquées, tout en se promettant de sortir 2 versions par an sans gestion de projet ? Tout ça bien sûr dans un projet logiciel dont les fondateurs et la première génération de développeurs sont passés à autre chose ?
Devinez !
Dégradation des fonctions basiques
Les années 2020 sont 40 ans trop tard pour ré-inventer les paradigmes d’interaction entre l’utilisateur et son ordinateur, que ce soit la façon dont on utilise son clavier et sa souris pour piloter une interface ou le comportement d’un navigateur de fichiers. Depuis les années 1980, toute l’informatique grand public a convergé vers une sémantique plus ou moins unifiée, où la touche échap ferme l’application courante, un double-clic ouvre un fichier, et où la roulette de la souris fait défiler la vue courante. Darktable1 prend un malin plaisir à ignorer tout ça, et les récents changements empirent les choses : il est désormais nécessaire de lire la documentation pour effectuer des tâches aussi simples que trier des fichiers ou assigner des raccourcis clavier à des actions dans l’interface.
Groupes de modules
Tout commence avec la refonte des groupes de modules , en 2020, qui cache la décision de ne pas décider d’une organisation unifiée des modules.
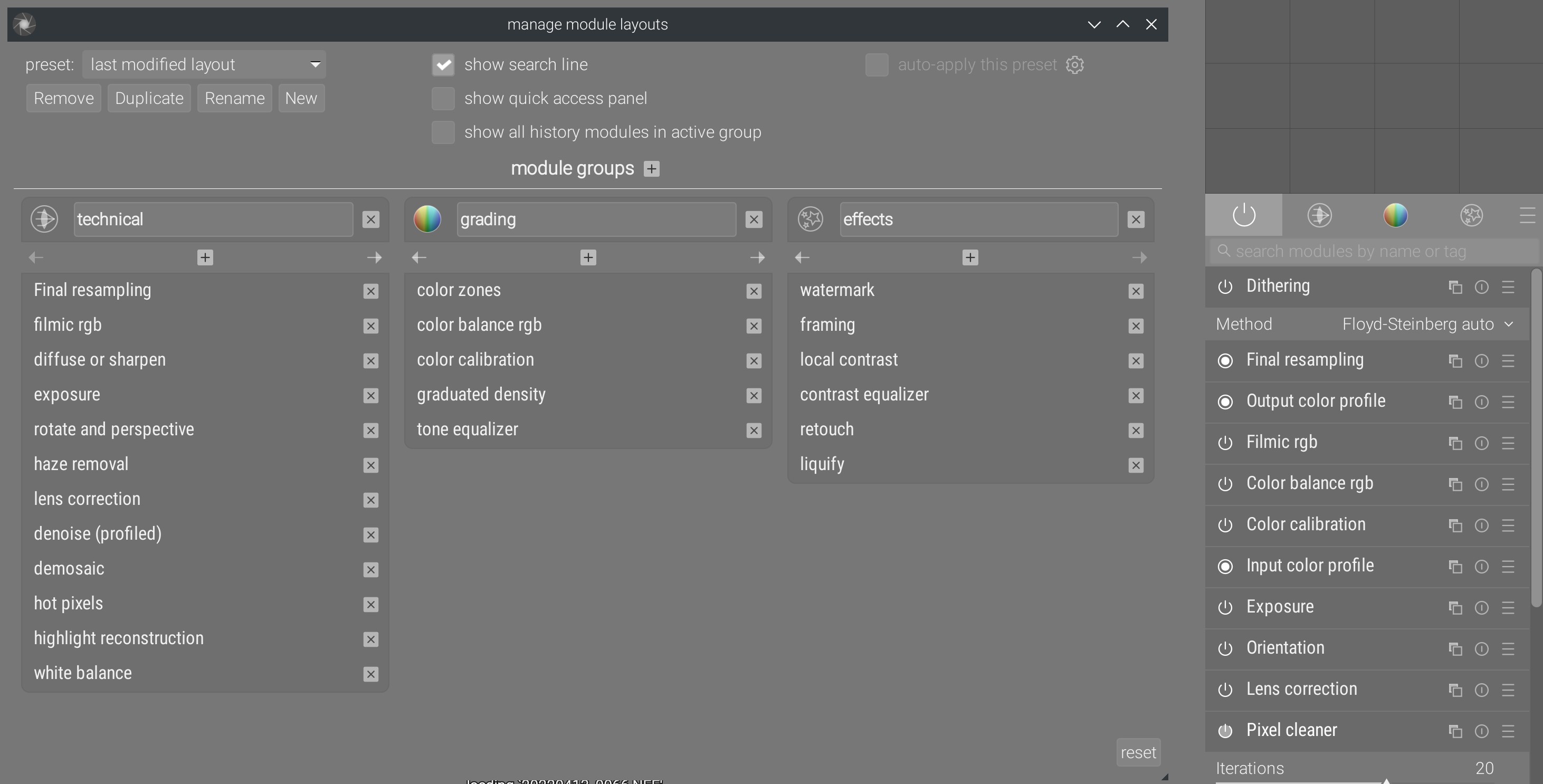
Depuis 2018 , je me bats pour nettoyer l’interface graphique de Darktable et en particulier l’organisation des modules. L’interface graphique devrait encourager les bonnes pratiques en disposant les outils dans l’ordre typique dans lequel ils devraient être utilisés. Les mauvaises pratiques sont celles qui augmentent les risques d’incohérences colorimétriques ou de retouche circulaire, où l’on doit revenir en arrière pour répercuter les changements effectués plus tard, même si elles peuvent fonctionner dans des cas simples. Dans le contexte du traitement d’image, tâche hautement technique où énormément de chose sont cachées à l’utilisateur sous l’interface, les bonnes pratiques servent à rendre des gens peu qualifiés capables d’utiliser le logiciel à moindres risques.
Cet ordre d’utilisation est principalement dicté par des considérations techniques telles que l’ordre d’application des modules dans la séquence du pipeline et l’utilisation de masques paramétriques et dessinés, dont l’effet dépend des modules appliqués en amont. Ignorer ces considérations techniques revient à chercher des problèmes, même si la grande mode des années 2010-20 est d’essaier de se faire croire que les technologies numériques fonctionnent détachées de toute réalité matérielle pour le seul bonheur de l’utilisateur.
Par exemple, la contrainte imposée sur le design du pipeline d’autoriser un ordre d’utilisation arbitraire des modules créée des problèmes mathématiquement insolubles en ce qui concerne le calcul des coordonnées des nœuds des masques, et aucune solution programmatique n’est possible (à part supprimer la contrainte…) parce que les maths ont dit non.
Sauf qu’une partie significative des utilisateurs programmeurs qui gravitent autour du projet sur Github et autour de la mailing-list développeurs reste convaincue qu’il n’y a ni bon ni mauvais workflow, juste des préférences personnelles, ce qui est probablement vrai quand vous pratiquez une discipline sans contrainte de temps, de budget ni de résultat. Ainsi, les modules devraient pouvoir se ré-ordonnancer à volonté, tant dans le pipeline que dans dans le workflow, et donc dans l’interface. La confusion vient du fait que la retouche non-destructive est vue à tort comme asynchrone (ce qui serait presque le cas si l’on n’utilisait ni masques ni mode de fusion) alors que le pipeline des pixels est séquentiel et plus proche d’une logique d’empilement de calques, telle qu’on la trouve dans Adobe Photoshop, Gimp, Krita, etc.
Découpler l’ordre des modules de leur ordre dans le pipeline revient autoriser toutes les utilisations même pathologiques, et à devoir écrire des pages et des pages de documentation pour mettre en garde, expliquer quoi faire, comment et pourquoi ; documentation que personne ne lira pour finir par reposer en boucle les mêmes questions sur les différents forums toutes les semaines.
Dans cette histoire, tout le monde perd son temps par la faute d’un design d’interface qui essaie d’être si souple qu’il ne peut être rendu robuste et sécuritaire par défaut. Dans le corps humain, chaque articulation dispose de certains degrés de liberté suivant certains axes ; si chaque articulation pouvait tourner à 340 ° sur chaque axe dans l’espace 3 D, l’ensemble serait instable car trop souple, et incapable de travailler en force. La métaphore s’applique au logiciel métier. On nage en plein culte du cargo libriste, qui aime avoir l’illusion du choix, c’est à dire se voir offrir de nombreuses options dont la plupart sont en fait inutilisables ou dangereuses, au détriment de la simplicité (KISS ), offertes à des utilisateurs dont la majorité ne comprend pas les implications de chaque option (et n’a pas la moindre envie de chercher à comprendre).
En l’absence de consensus sur l’ordonnancement des modules dans l’interface, un outil compliqué, peu fiable et lourd a été introduit fin 2020 pour permettre à chaque utilisateur de configurer la présentation des modules en onglets. Il est muni de nombreuses options inutiles et stocke la disposition courante dans la base de données en utilisant le nom traduit des modules, ce qui fait que changer la langue de l’interface fait perdre les pré-réglages. Entièrement configurable, il permet aux utilisateurs de choisir comment se faire mal, sans aucun guide de bonne pratique. Cette immondice est codée sur près de 4000 lignes mélangeant allègrement des requêtes SQL au milieu du code d’interface GTK , et les presets sont créés via des macros compilateur redondantes , alors que les modules ont tous depuis longtemps un drapeau binaire permettant de régler leur groupe par défaut de façon… modulaire.
Et plus important, il remplace une fonctionnalité simple et efficace, disponible jusque dans Darktable 3.2 :
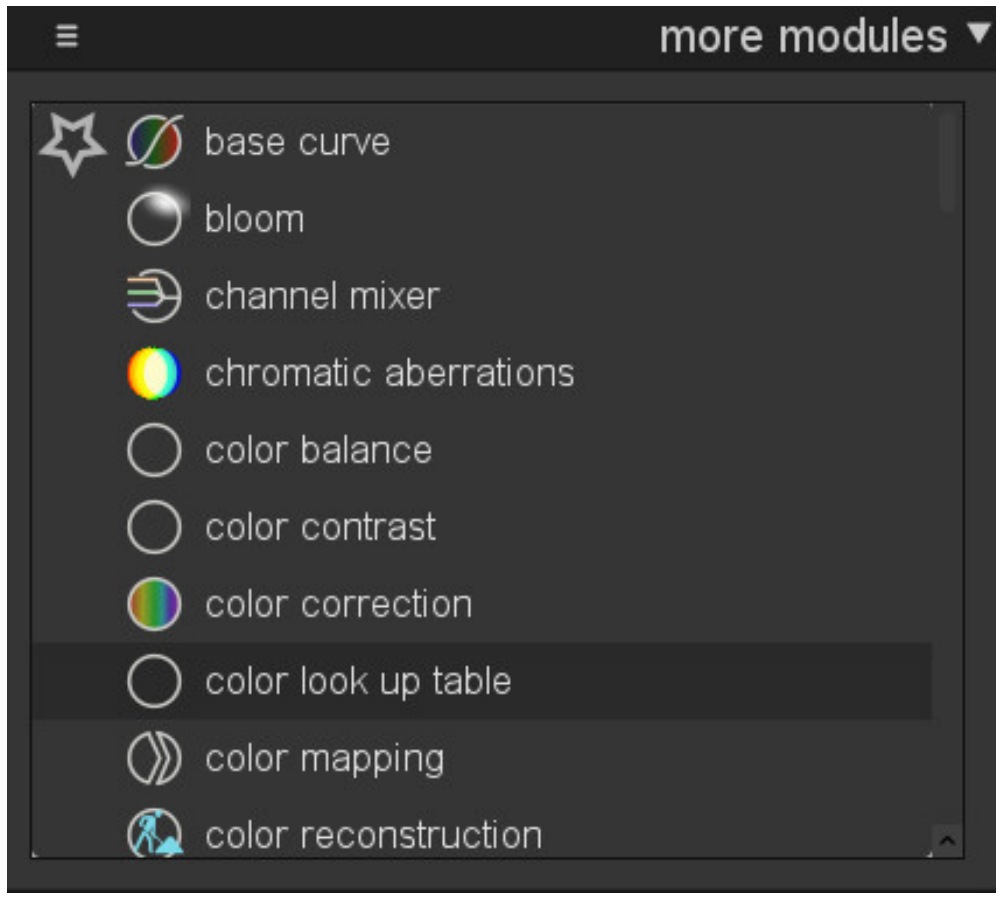
Un clic sur le nom du module l’active, un deuxième l’ajoute dans la colonne des modules favoris, un troisième le cache de l’interface. Le tout permettant des pré-réglages et stockant la vue courante en texte pur dans le fichier darktablerc. Simple et robuste, codée en 688 lignes de code lisible et bien structuré, la fonctionnalité n’est donc pas assez amusante pour le développeur quincagénaire dilettante et il était urgent de la remplacer par une usine à gaz.
Raccourcis clavier
En 2021 est ajouté ce que j’appelle le grand turducken MIDI. Il s’agit d’étendre l’interface de gestion des raccourcis claviers (déjà étendue en 2019 pour permettre le support des « raccourcis dynamiques », c’est à dire des actions combinées souris + clavier) pour supporter les périphériques MIDI et… les manettes de jeux vidéos.
Fin 2022, soit un an et demi après cette fonctionnalité, dans le sondage que j’ai réalisé , moins de 10 % des utilisateurs possèdent un périphérique MIDI, et seulement 2 % l’utilisent pour Darktable. À comparer avec les 45 % d’utilisateurs qui possèdent une tablette graphique (type Wacom), dont le support par Darktable est toujours si bancal que 6 % seulement l’utilisent. En dehors d’un problème de priorité, ce que je ne tolère pas ici, ce sont les effets de bords introduits par ce changement et le coût global qu’il a eu, à commencer par le fait qu’il n’importe pas les raccourcis utilisateur définis dans les versions 3.2 et antérieures, et qu’il rend la configuration de nouveaux raccourcis terriblement compliquée.
Avant le grand turducken, seule une liste restreinte de contrôles graphiques pouvaient être mappées vers des raccourcis claviers ou mixtes (clavier + souris). Cette liste était manuellement sélectionnée par les développeurs. Le grand turducken MIDI introduit permet de conecter tous les contrôles GUI vers des raccourcis, présentant à l’utilisateur une liste de plusieurs milliers d’éléments à configurer, dans laquelle il est difficile de trouver les 3 dont vous avez vraiment besoin, et le moteur de recherche textuel est trop basique pour être utile :
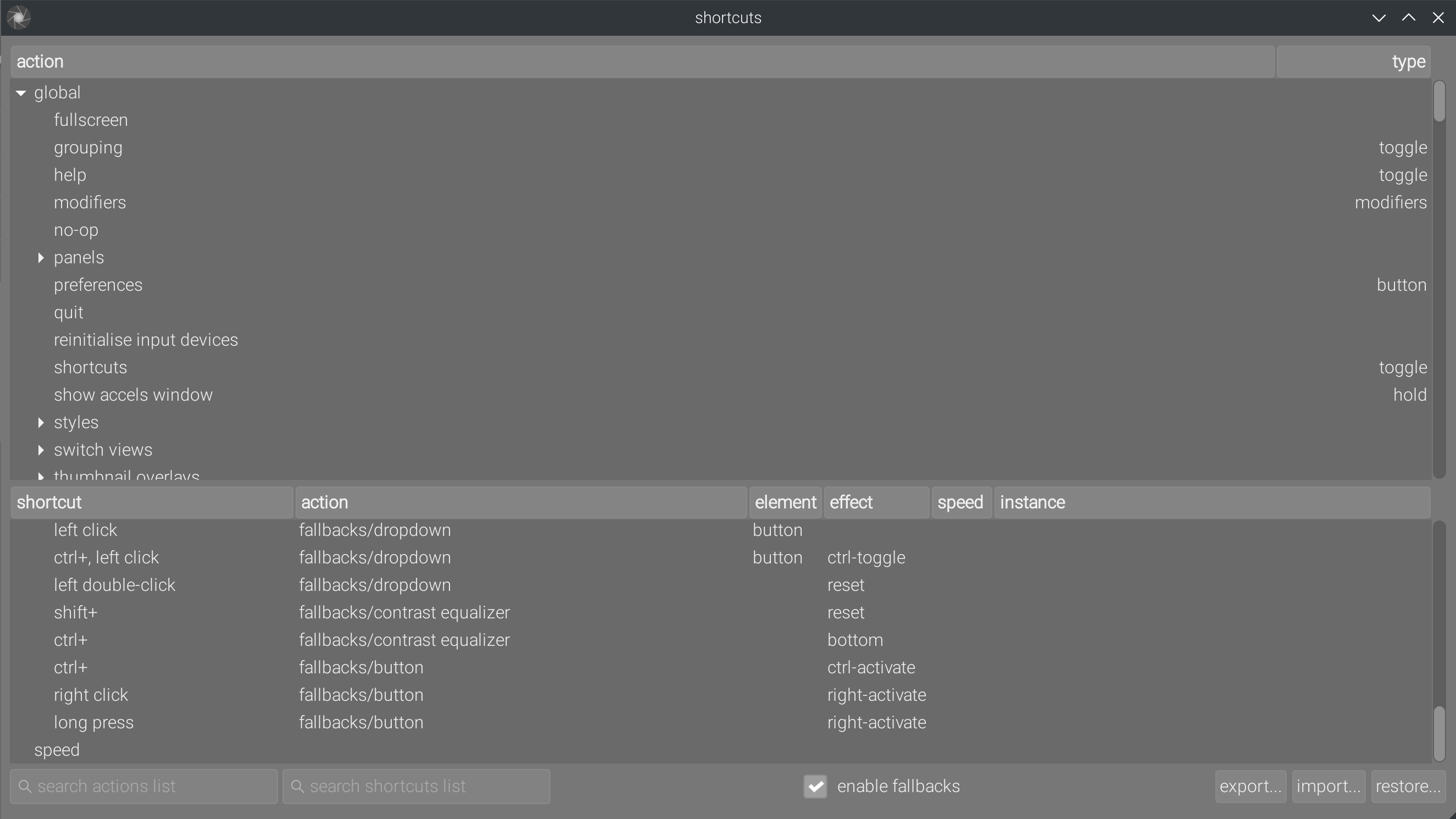
Notez le recours aux « effets », sur lesquels la documentation est d’un piètre secours. C’est par déduction (parce le code n’est pas commenté non plus ) que j’ai fini par comprendre qu’il s’agit d’émulations d’interactions bureautiques classiques (clic et clavier) destinées à être utilisées avec les périphériques MIDI et consoles de jeu (il faudra quand même m’expliquer la signification de Ctrl-Toggle, Right-activate ou Right-Toggle en termes d’interaction bureautique standard).
Ce qui est inadmissible, c’est que l’usage du pavé numérique est cassé par design , notamment pour attribuer des notes chiffrées (étoiles) aux miniatures en table lumineuse. En effet, les touches modificatrices (verrouillage numérique et majuscule) ne sont pas correctement décodées par le bazar, et les chiffres sont traités différemment selon qu’ils sont entrés depuis le clavier “textuel” ou depuis le pavé numérique. Le 1 du pavé numérique est donc invariablement décodé comme un Keypad End, peu importe l’état du verrouillage numérique. Voici donc comment j’ai dû configurer les raccourcis numériques avec un clavier BÉPO et dupliquer la configuration pour le pavé numérique :
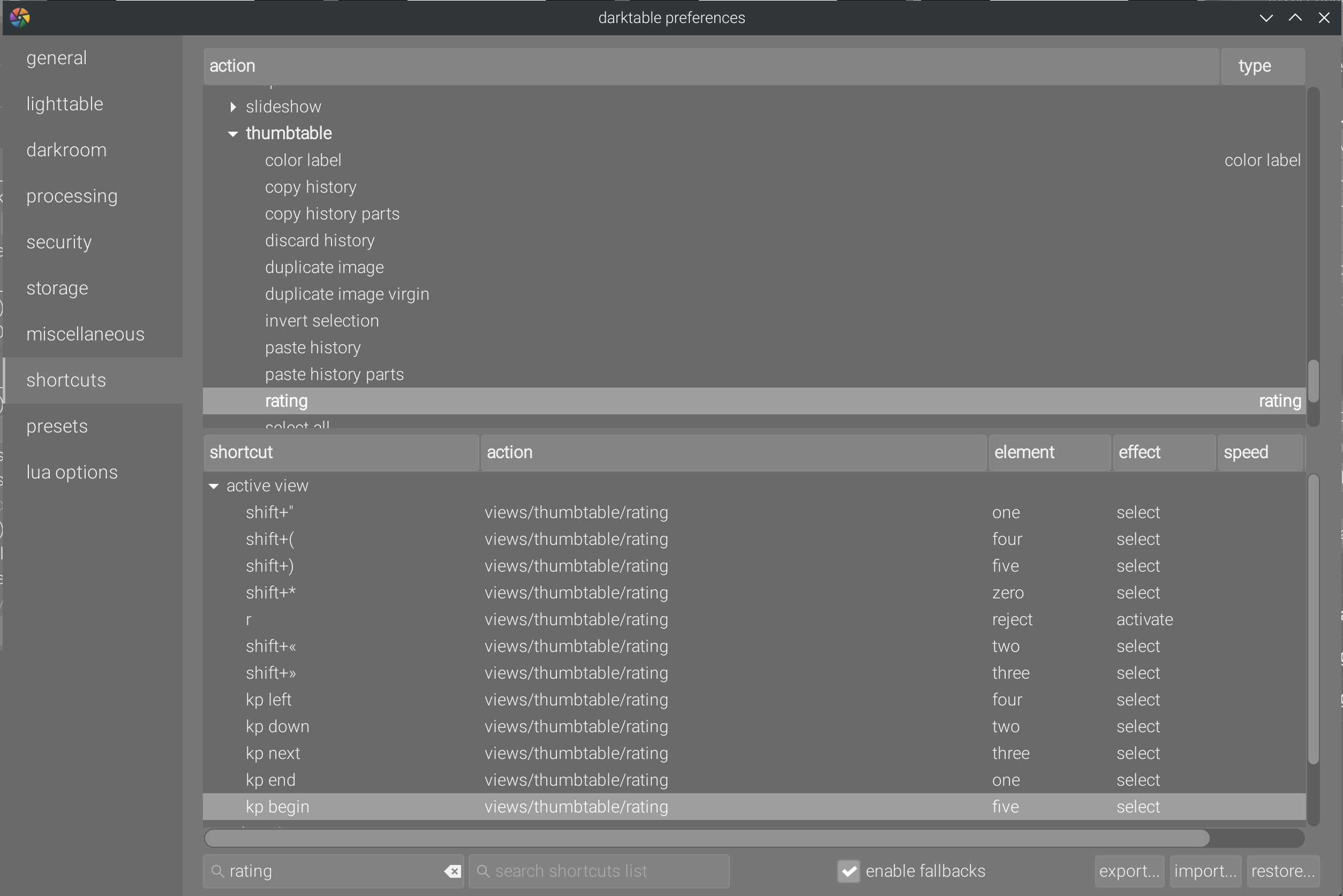
Il faut juste se souvenir que Shift+" et Kp End signifient tous deux 1 et penser à dupliquer tous les raccourcis pour le pavé numérique et pour le reste du clavier. En clair, on casse une attente utilisateur des plus basiques, et on envoie paître les critiques sur le design. La régression est mentionnée sur tous les forums Darktable mais n’inquiète personne.
La correction de ce bug cette fonctionnalité a été faite sur Ansel et les touches du pavé numérique sont remappées vers des touches standard directement dans le code , pour un total de 100 lignes de code, commentaires inclus. Effectuer cette correction a été très difficile : j’ai lu la documentation Gtk et j’ai pompé ligne à ligne leur exemple. 2 ans que ça traîne, pour ça…
La cerise sur le gâteau est que, encore une fois, on a remplacé 1306 lignes de code clair et structuré par une horreur de près de 4400 lignes remplie de pépites, comme :
1. La boucle while de la mort (source ) :
1 gboolean applicable;
2 while((applicable =
3 (c->key_device == s->key_device && c->key == s->key && c->press >= (s->press & ~DT_SHORTCUT_LONG) &&
4 ((!c->move_device && !c->move) ||
5 (c->move_device == s->move_device && c->move == s->move)) &&
6 (!s->action || s->action->type != DT_ACTION_TYPE_FALLBACK ||
7 s->action->target == c->action->target))) &&
8 !g_sequence_iter_is_begin(*current) &&
9 (((c->button || c->click) && (c->button != s->button || c->click != s->click)) ||
10 (c->mods && c->mods != s->mods ) ||
11 (c->direction & ~s->direction ) ||
12 (c->element && s->element ) ||
13 (c->effect > 0 && s->effect > 0 ) ||
14 (c->instance && s->instance ) ||
15 (c->element && s->effect > 0 && def &&
16 def->elements[c->element].effects != def->elements[s->element].effects ) ))
17 {
18 *current = g_sequence_iter_prev(*current);
19 c = g_sequence_get(*current);
20 }2. Le switch case contenant des if imbriqués sur 2 niveaux (source ) :
1 switch(owner->type)
2 {
3 case DT_ACTION_TYPE_IOP:
4 vws = DT_VIEW_DARKROOM;
5 break;
6 case DT_ACTION_TYPE_VIEW:
7 {
8 dt_view_t *view = (dt_view_t *)owner;
9
10 vws = view->view(view);
11 }
12 break;
13 case DT_ACTION_TYPE_LIB:
14 {
15 dt_lib_module_t *lib = (dt_lib_module_t *)owner;
16
17 const gchar **views = lib->views(lib);
18 while(*views)
19 {
20 if (strcmp(*views, "lighttable") == 0)
21 vws |= DT_VIEW_LIGHTTABLE;
22 else if(strcmp(*views, "darkroom") == 0)
23 vws |= DT_VIEW_DARKROOM;
24 else if(strcmp(*views, "print") == 0)
25 vws |= DT_VIEW_PRINT;
26 else if(strcmp(*views, "slideshow") == 0)
27 vws |= DT_VIEW_SLIDESHOW;
28 else if(strcmp(*views, "map") == 0)
29 vws |= DT_VIEW_MAP;
30 else if(strcmp(*views, "tethering") == 0)
31 vws |= DT_VIEW_TETHERING;
32 else if(strcmp(*views, "*") == 0)
33 vws |= DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
34 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
35 views++;
36 }
37 }
38 break;
39 case DT_ACTION_TYPE_BLEND:
40 vws = DT_VIEW_DARKROOM;
41 break;
42 case DT_ACTION_TYPE_CATEGORY:
43 if(owner == &darktable.control->actions_fallbacks)
44 vws = 0;
45 else if(owner == &darktable.control->actions_lua)
46 vws = DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
47 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
48 else if(owner == &darktable.control->actions_thumb)
49 {
50 vws = DT_VIEW_DARKROOM | DT_VIEW_MAP | DT_VIEW_TETHERING | DT_VIEW_PRINT;
51 if(!strcmp(action->id,"rating") || !strcmp(action->id,"color label"))
52 vws |= DT_VIEW_LIGHTTABLE; // lighttable has copy/paste history shortcuts in separate lib
53 }
54 else
55 fprintf(stderr, "[find_views] views for category '%s' unknown\n", owner->id);
56 break;
57 case DT_ACTION_TYPE_GLOBAL:
58 vws = DT_VIEW_DARKROOM | DT_VIEW_LIGHTTABLE | DT_VIEW_TETHERING |
59 DT_VIEW_MAP | DT_VIEW_PRINT | DT_VIEW_SLIDESHOW;
60 break;
61 default:
62 break;
63 }3. Le switch case imbriqué du démon, avec des clauses additives sournoisement dissimulées (source ) :
1case DT_ACTION_ELEMENT_ZOOM:
2 ;
3 switch(effect)
4 {
5 case DT_ACTION_EFFECT_POPUP:
6 dt_bauhaus_show_popup(widget);
7 break;
8 case DT_ACTION_EFFECT_RESET:
9 move_size = 0;
10 case DT_ACTION_EFFECT_DOWN:
11 move_size *= -1;
12 case DT_ACTION_EFFECT_UP:
13 _slider_zoom_range(bhw, move_size);
14 break;
15 case DT_ACTION_EFFECT_TOP:
16 case DT_ACTION_EFFECT_BOTTOM:
17 if((effect == DT_ACTION_EFFECT_TOP) ^ (d->factor < 0))
18 d->max = d->hard_max;
19 else
20 d->min = d->hard_min;
21 gtk_widget_queue_draw(widget);
22 break;
23 default:
24 fprintf(stderr, "[_action_process_slider] unknown shortcut effect (%d) for slider\n", effect);
25 break;
26 }Les programmeurs comprennent de quoi je parle, pour les autres, sachez que je ne comprends guère plus que vous ce que ça fait : c’est du code de merde et si plusieurs bugs ne sont pas cachés là-dedans, ça sera de la pure chance. Chasser des bugs dans ce merdier relève de l’archéologie de fond d’égoût, d’autant plus que Darktable n’a pas de documentation développeur, et que faute de commentaires parlants dans le code, toute modification dudit code commence nécessairement par une phase de rétro-ingéniérie qui devient de plus en plus compliquée à mesure que le temps passe.
Le vrai problème de ce genre de code, c’est qu’on ne peut pas l’améliorer sans le réécrire plus ou moins complètement : pour le corriger, il faut d’abord le comprendre, et la raison pour laquelle on doit le corriger, est précisément parce qu’il est incompréhensible et dangereux à long terme. On appelle ça de la dette technique . En clair, tout le travail investi dans cette fonctionnalité va créer du travail additionnel parce qu’il est déraisonnable de garder du code de ce type au milieu d’une base de code de plusieurs centaines de milliers de lignes sans s’attendre à ce que ça nous explose à la face un jour.
C’est d’autant plus ridicule dans le contexte d’une application open-source où l’essentiel du personnel n’est même pas programmeur de formation. Le développeur intelligent écrit du code compréhensible par des idiots, et réciproquement.
Filtres de collections
Jusqu’à Darktable 3.8, les filtres de collections, en haut dans la table lumineuse, servaient à restreindre temporairement la vue sur une collection. La collection est une extraction de la base de données des photos selon certains critères, le plus courant étant d’extraire le contenu de tout un dossier (que Darktable nomme “pellicule” pour confondre tout le monde, car en fait une pelliculle est le contenu d’un dossier affiché sous forme de liste au lieu d’une arborescence – plein de gens croient donc à tort que Darktable n’a pas de gestionnaire de fichiers).
Étant utilisateur de Darktable depuis plus d’une décennie, j’ai une base de données de plus de 140 000 entrées. Extraire une collection parmi ces 140 000 images est une opération lente. Mais mes dossiers contiennent rarement plus de 300 images. Filtrer, par exemple, les photos notées 2 étoiles ou plus, parmi une collection de 300 fichiers est rapide parce que c’est un sous-ensemble de 300 éléments. Et passer d’un filtre à l’autre l’est également. Le filtre n’est donc qu’une vue partielle ou totale d’une collection, optimisée pour un usage marche/arrêt rapide et temporaire.
Sous couvert de refactoriser le code de filtrage, qui prenait en tout et pour tout 550 lignes , le Gaston Lagaffe en chef de Darktable s’est attelé à briser ce modèle pour transformer les filtres en collections comme les autres, au moyen de plus de 6000 lignes de code sans compter les innombrables correctifs de bugs qui n’ont fait qu’ajouter des lignes2. Le tout, comme d’habitude, hautement configurable et redondant avec le classique module collections qui est resté là, et servi par des icônes tellement peu claires qu’il a fallu ajouter des infobulles textuelles pour en clarifier le sens.
Dans ce code de qualité, on trouvera le sempiternel while sous le switch case dans le if dans le if dans le for (source ) :
1for(int k = 0; k < num_rules; k++)
2 {
3 const int n = sscanf(buf, "%d:%d:%d:%d:%399[^$]", &mode, &item, &off, &top, str);
4
5 if(n == 5)
6 {
7 if(k > 0)
8 {
9 c = g_strlcpy(out, "<i> ", outsize);
10 out += c;
11 outsize -= c;
12 switch(mode)
13 {
14 case DT_LIB_COLLECT_MODE_AND:
15 c = g_strlcpy(out, _("AND"), outsize);
16 out += c;
17 outsize -= c;
18 break;
19 case DT_LIB_COLLECT_MODE_OR:
20 c = g_strlcpy(out, _("OR"), outsize);
21 out += c;
22 outsize -= c;
23 break;
24 default: // case DT_LIB_COLLECT_MODE_AND_NOT:
25 c = g_strlcpy(out, _("BUT NOT"), outsize);
26 out += c;
27 outsize -= c;
28 break;
29 }
30 c = g_strlcpy(out, " </i>", outsize);
31 out += c;
32 outsize -= c;
33 }
34 int i = 0;
35 while(str[i] != '\0' && str[i] != '$') i++;
36 if(str[i] == '$') str[i] = '\0';
37
38 gchar *pretty = NULL;
39 if(item == DT_COLLECTION_PROP_COLORLABEL)
40 pretty = _colors_pretty_print(str);
41 else if(!g_strcmp0(str, "%"))
42 pretty = g_strdup(_("all"));
43 else
44 pretty = g_markup_escape_text(str, -1);
45
46 if(off)
47 {
48 c = snprintf(out, outsize, "<b>%s</b>%s %s",
49 item < DT_COLLECTION_PROP_LAST ? dt_collection_name(item) : "???", _(" (off)"), pretty);
50 }
51 else
52 {
53 c = snprintf(out, outsize, "<b>%s</b> %s",
54 item < DT_COLLECTION_PROP_LAST ? dt_collection_name(item) : "???", pretty);
55 }
56
57 g_free(pretty);
58 out += c;
59 outsize -= c;
60 }
61 while(buf[0] != '$' && buf[0] != '\0') buf++;
62 if(buf[0] == '$') buf++;
63 }et autres if imbriqués sur deux niveaux dans des switch case nécessaires au support des raccourcis clavier (source ).
Cette dernière saloperie a été la goutte d’eau qui a fait déborder le vase et m’a fait forker Ansel. Je refuse de continuer à travailler sur une bombe à retardement dans une équipe qui ne voit pas le problème et qui fait mumuse avec du code sur son temps libre. Coder les amuse peut-être, moi pas. Et réparer les conneries de gamins irresponsables qui ont deux fois mon âge, surtout quand ils cassent des trucs que j’ai nettoyé il y a 3 ou 4 ans, me met en rage.
Table lumineuse
La table lumineuse a subi deux ré-écritures quasi complètes, la première début 2019, visant à optimiser le code pour rendre la vue plus rapide, la deuxième fin 2019, qui ajoute de nombreuses fonctionnalités discutables dont la vue sélection .
Rapidement, le mode sélection est décomposé en deux modes : la sélection dynamique et la sélection statique, qui gèrent le nombre d’images différemment. Beaucoup d’utilisateurs n’ont toujours pas compris la différence 4 ans plus tard. On a donc alors la vue par défaut (gestionnaire de fichier), la vue table lumineuse zoomable (que personne n’utilise), la vue sélection statique, sélection dynamique, et le mode prévisualisation (une seule image en plein écran).
Puis de nouvelles options d’apparence sont ajoutées aux miniatures de la table lumineuse, permettant de définir les surimpressions : surimpressions permanentes basiques, surimpressions permanentes avec infos EXIF étendues, les mêmes mais affichées seulement au survol, et enfin au survol temporisées (avec minuterie réglable).
Le code d’interface qui fait le rendu des miniatures et de leur surimpressions doit donc tenir compte de 5 vues différentes et de 7 variantes d’affichages , soit 35 combinaisons possibles. Le code qui assure le redimensionnement correct des miniatures fait donc 220 lignes à lui seul .
Mais ça ne s’arrête pas là, puisque le code de rendu graphique des miniature est partagé également avec la barre “pellicule”, ce qui fait en fait 36 combinaisons possibles dans le rendu des miniatures. Multiplié par 3 thèmes de couleur de base, ça fait donc 108 jeux d’instructions CSS pour styliser l’interface entièrement… dont beaucoup de combinaisons ont été oubliées dans la grande refonte graphique de Darktable 4.0 , et comment aurait-il pu en être autrement ?
Dans Darktable 2.6, on avait donc 4193 lignes pour l’ensemble, qui ne comportait que la vue gestionnaire de fichier, table lumineuse zoomable et prévisualisation plein écran avec deux modes d’affichage des surimpressions (toujours visible ou visible au survol) :
- 2634 lignes dans views/lighttable.c pour la vue table lumineuse et le rendu des miniatures,
- 1124 lignes dans libs/tools/filmstrip.c pour la barre pellicule, dont une partie duplique partiellement le code de la table lumineuse, en ce qui concerne le rendu des miniatures,
- 435 lignes dans libs/tools/global_toolbox.c , pour le menu de boutons permettant d’activer ou désactiver l’affichage des surimpressions.
Après Darktable 3.0 et l’ajout des modes de sélection, on passe à 6731 lignes :
- 5149 lignes dans views/lighttable.c ,
- 1177 lignes dans libs/tools/filmstrip.c ,
- 405 lignes dans libs/tools/global_toolbox.c .
Après Darktable 3.2 et l’ajout des 7 variantes de surimpressions hautement configurables et la refactorisation du code, on passe à 8380 lignes :
- 1463 lignes dans views/lighttable.c ,
- 1642 lignes dans dtgtk/culling.c , où les fonctionnalités des vues sélection ont été détachées,
- 2447 lignes dans dtgtk/thumbtable.c , où sont gérés les conteneurs de miniatures pour la table lumineuse et de la barre pellicule,
- 1736 lignes dans dtgtk/thumbnail.c , où sont gérées les miniatures en elles-mêmes,
- 169 lignes dans dtgtk/thumbnail_btn.c , où sont déclarés des boutons spécifiques aux miniatures,
- 115 lignes dans libs/tools/filmstrip.c ,
- 808 lignes dans libs/tools/global_toolbox.c .
Dans Darktable 4.2, après correction de nombreux bugs, on arrive à un total de 9264 lignes :
- 1348 lignes dans views/lighttable.c ,
- 1828 lignes dans dtgtk/culling.c ,
- 2698 lignes dans dtgtk/thumbtable.c ,
- 2093 lignes dans dtgtk/thumbnail.c ,
- 166 lignes dans dtgtk/thumbnail_btn.c ,
- 109 lignes dans libs/tools/filmstrip.c ,
- 1022 lignes dans libs/tools/global_toolbox.c .
Le nombre de lignes (surtout dans du code qui prend à malin plaisir à ignorer les bonnes pratiques de programmation) est un indicateur direct de la difficulté à débugger quoi que ce soit là dedans, mais également un indice indirect (dans le cas de code d’interface graphique) de la charge CPU requise pour faire tourner le logiciel.
En effet, si vous démarrez darktable -d sql et que vous survolez une miniature de la table lumineuse, vous allez obtenir en console :
1140.8252 [sql] darktable/src/common/image.c:311, function dt_image_film_roll(): prepare "SELECT folder FROM main.film_rolls WHERE id = ?1"
2140.8259 [sql] darktable/src/common/image.c:387, function dt_image_full_path(): prepare "SELECT folder || '/' || filename FROM main.images i, main.film_rolls f WHERE i.film_id = f.id and i.id = ?1"
3140.8271 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
4140.8273 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
5140.8275 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
6140.8277 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
7140.8279 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
8140.8280 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
9140.8282 [sql] darktable/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
10140.8284 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
11140.8286 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
12140.9512 [sql] darktable/src/common/act_on.c:156, function _cache_update(): prepare "SELECT imgid FROM main.selected_images WHERE imgid=104337"
13140.9547 [sql] darktable/src/common/act_on.c:156, function _cache_update(): prepare "SELECT imgid FROM main.selected_images WHERE imgid=104337"
14140.9550 [sql] darktable/src/common/act_on.c:288, function dt_act_on_get_query(): prepare "SELECT imgid FROM main.selected_images WHERE imgid =104337"
15140.9552 [sql] darktable/src/libs/metadata.c:263, function _update(): prepare "SELECT key, value, COUNT(id) AS ct FROM main.meta_data WHERE id IN (104337) GROUP BY key, value ORDER BY value"
16140.9555 [sql] darktable/src/common/collection.c:973, function dt_collection_get_selected_count(): prepare "SELECT COUNT(*) FROM main.selected_images"
17140.9556 [sql] darktable/src/libs/image.c:240, function _update(): prepare "SELECT COUNT(id) FROM main.images WHERE group_id = ?1 AND id != ?2"
18140.9558 [sql] darktable/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (104337) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"ce qui veut dire que 18 requêtes SQL sont faites dans la base de données, destinées à récupérer les informations de l’image, et démarrées à chaque fois que le curseur survole une nouvelle miniature dans la table lumineuse, pour aucune raison car les métadonnées n’ont pas changé depuis le précédent survol.
Dans Ansel, en retirant la plupart des options, j’ai réussi à économniser 7 requêtes, ce qui n’empêche pas les requêtes dupliquées mais améliore tout de même les timings (les timestamps sont les nombres en début de ligne) :
112.614534 [sql] ansel/src/common/image.c:285, function dt_image_film_roll(): prepare "SELECT folder FROM main.film_rolls WHERE id = ?1"
212.615225 [sql] ansel/src/common/image.c:356, function dt_image_full_path(): prepare "SELECT folder || '/' || filename FROM main.images i, main.film_rolls f WHERE i.film_id = f.id and i.id = ?1"
312.616499 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
412.616636 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
512.616769 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
612.616853 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
712.616930 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
812.617007 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
912.617084 [sql] ansel/src/common/metadata.c:487, function dt_metadata_get(): prepare "SELECT value FROM main.meta_data WHERE id = ?1 AND key = ?2 ORDER BY value"
1012.617205 [sql] ansel/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (133727) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"
1112.617565 [sql] ansel/src/common/tags.c:635, function dt_tag_get_attached(): prepare "SELECT DISTINCT I.tagid, T.name, T.flags, T.synonyms, COUNT(DISTINCT I.imgid) AS inb FROM main.tagged_images AS I JOIN data.tags AS T ON T.id = I.tagid WHERE I.imgid IN (133727) AND T.id NOT IN memory.darktable_tags GROUP BY I.tagid ORDER by T.name"Le problème est que le code source imbrique des commandes SQL à l’intérieur des fonctions qui dessinent l’interface graphique, et déméler ce fouillis à travers les différentes couches héritées de la “refactorisation” (censée simplifier le code, mais en fait non) est encore une fois de l’archéologie. Et si le problème avait été réglé quand tout le code faisait 6700 lignes sur 3 fichiers, on n’en serait pas, 4 ans plus tard, à en chercher les causes dans 2500 lignes de plus dans 7 fichiers différents (sans compter les fichiers d’en-tête .h).
On est sur un cas de figure où la “refactorisation” a en réalité complexifié le code et où fusionner le code de rendu des miniatures entre la barre pellicule et la table lumineuse n’a fait qu’ajouter des if (branchements) internes à plusieurs niveaux qui en compliquent encore la structure, juste pour obéir aveuglément au principe de réutilisation du code qui vient ici en conflit avec le principe de modularité , et qu’un développeur compétent aurait résolu par un héritage , ce qui n’est pas facile à faire en C mais tout à fait possible (et Darktable utilise ce principe dans du code de 2009-10).
Le cosmétique prend le dessus sur la stabilité
Darktable 4.2 introduit la prévisualisation des styles dans la chambre noire. Ça serait génial si les styles n’étaient pas cassés en profondeur, lorsqu’utilisés avec un ordre du pipeline non standard ou des instances multiples de modules. Le problème est qu’une solution propre et pérenne passe par la théorie des graphes orientés , et là forcément, on a perdu nos pisseurs de code copié-collé.
Dans le même esprit, on a de grosses incohérences sur les copier-coller d’historique en mode écraser lorsque des presets utilisateur par défaut sont également utilisés (notamment dans les module balance des blancs). Mais c’est bien plus amusant de saloper l’interface, alors ça restera là encore longtemps.
Darktable 3.6 et 3.8 ont introduit pleins de variantes de l’histogramme : vectorscope, forme d’onde verticale, espaces de couleurs avancés et exotiques. Sauf que si vous lancez darktable -d perf en console et que vous allez en chambre noire, vous allez voir quantité de
à chaque fois que vous bougez le curseur dans la fenêtre (et même pas forcément sur l’histogramme). C’est l’histogramme qui est redessiné à chaque interaction de la souris avec la fenêtre. Le même problème affecte de nombreux éléments graphiques custom et sa cause est non-identifiée. Notez qu’il n’affecte pas Ansel, donc la cause devait être logée quelque part dans les 23 000 lignes de code que j’ai viré.
Par 2 fois, j’ai essayé de refactoriser l’immondice qu’est devenue cette fonctionnalité , mais une nouvelle fonctionnalité plus urgente a été poussée à chaque fois en invalidant mon travail. J’ai fini par laisser tomber.
Le niveau de pourrissement atteint par l’histogramme est tel qu’une ré-écriture complète prendrait moins de temps qu’une refactorisation, surtout que l’histogramme est prélevé bien trop tard dans le pipeline, dans l’espace de couleur écran, ce qui rend le définition d’un espace de couleur histogramme caduque étant donné que le gamut est écrêté dans l’espace écran quoi qu’il arrive. Et devinez quoi… Darktable 4.4 aura encore plus d’options, avec la possibilité de définir des harmonies de couleur (fondamental pour les geeks qui font de la peinture au numéro et retouchent des histogrammes).
Reste qu’à chaque fois que vous bougez la souris, un grand nombre de recalculs superflus sont démarrés pour rien. À quel point c’est mal ? Je me suis amusé à mesurer la consommation CPU de mon système au repos, avec l’utilitaire Linux powertop. Le protocole est simple : un ordinateur portable (CPU Intel Xeon Mobile de 6 e génération) sur batterie en mode éco, rétroéclairage écran au minimum, on ouvre l’application, on ne touche à rien pendant 4 min et on regarde la consommation CPU globale du système telle que rapportée par powertop au cours de la 5 e minute :
- Système de base (pas d’application ouverte à part
powertopdans un terminal) : 3,0 à 3,5 % CPU - Ansel :
- ouvert sur la table lumineuse : 2,9 à 3,4 % CPU,
- ouvert sur la chambre noire : 3,8 à 4,5 % (avant restauration des groupes de modules à Darktable 3.2),
- ouvert sur la chambre noire : 3,0 à 3,5 % CPU (après restauration des groupes de modules),
- Darktable :
- ouvert sur la table lumineuse : 6,6 à 7,1 % CPU,
- ouvert sur la chambre noire : 30,9 à 44,9 % CPU (non, ce n’est pas une erreur de virgule),
Je ne comprends pas ce que Darktable calcule lorsqu’on le laisse ouvert sans toucher à l’ordinateur, parce qu’il n’y a rien à calculer. Darktable en table lumineuse consomme à lui seul autant que tout le système Fedora 37 + l’environnement de bureau KDE + un gestionnaire de mot de passe tiers et un client Nextcloud qui tournent en tâche de fond, et il consomme 10 fois plus que tout le système lorsqu’ouvert en chambre noire.
Tout ceci pointe vers du code d’interface graphique très buggé. Dans Ansel, j’ai retiré une grande partie du code sale, sans pour autant optimiser quoi que ce soit par ailleurs, et ces chiffres ne font que valider mon choix : le code sale cache des problèmes indétectables à la lecture, et on ne peut pas continuer comme ça.
Je suis apparemment le seul à trouver anormal de priver le pixel pipeline de ⅓ à ½ de la puissance CPU pour peinturlurer une stupide interface. En tout état de cause, il n’y a aucune raison valable pour qu’un logiciel qu’on laisse ouvert sans y toucher transforme un ordinateur en grille-pain, surtout depuis qu’on n’achète plus de gaz russe.
Travailler contre soi même
Nous sommes photographes. Le fait que nous ayons besoin d’un ordinateur pour faire de la photographie est une nouveauté (depuis 20 ans) liée à la technologie d’imagerie numérique qui a remplacé pour toutes sortes de raisons (bonnes et mauvaises) une technologie vieille de 160 ans, connue et maîtrisée. Dans le processus, le fait qu’on ait besoin d’un ordinateur et d’un logiciel pour produire des images est de l’overhead pur et simple. Forcer les gens qui ne comprennent pas comment fonctionne un ordinateur à passer par lui pour effectuer des tâches qu’ils pouvaient parfaitement exécuter manuellement auparavant est aussi une forme d’oppression, et le faire passer pour un progrès technique est une forme de violence psychologique.
Et qui dit logiciel dit développement, maintenance, documentation et gestion de projet. Encore plusieurs couches d’overhead par dessus l’overhead. Or le fait que la main d’œuvre d’un projet open-source ne demande pas de rémunération ne doit pas faire oublier que le temps passé (perdu ?) sur le logiciel, son utilisation, son développement, sa maintenance est en lui-même un coût non récupérable.
Les quelques exemples ci-dessus donnent un aperçu de la complexification du code source, mais aussi de sa dégradation au cours du temps en terme de qualité, car des fonctionnalités basiques et robustes sont remplacées par du code spaghetti confus et sournoisement buggé. Derrière ce problème de lisibilité, c’est finalement une dégradation de la maintenabilité à moyen terme qui n’augure rien de bon pour le futur du projet, avec l’approbation du mainteneur.
Depuis 4 ans que je travaille à temps plein sur Darktable, 2022 est la première année où je suis pratiquement incapable d’identifier la source de la plupart des bugs d’interface, tant la logique de fonctionnement est devenue tordue et le code incompréhensible. Le nombre de bugs réglés est également en constante baisse, à la fois en valeur absolue et en ratio du nombre de pull requests, alors que le volume de code changé reste à peu près constant (note : les décomptes de lignes de code suivantes incluent seulement les fichiers C/C++/OpenCL et le XML génératif et excluent les commentaires) :
- 3.0 (Décembre 2019, un an après 2.6)
- 1049 problèmes ouverts , 66 problèmes fermés / 553 pull requests fusionnées (12 %),
- 398 fichiers changés, 66 k insertions, 22 k délétions, (net : +44 k lignes),
- 3.2 (Août 2020)
- 1028 problèmes ouverts , 92 problèmes fermés / 790 pull requests fusionnées (12 %),
- 586 fichiers changés, 54 k insertions, 43 k délétions (net : +2 k lignes),
- 3.4 (Décembre 2020)
- 981 problèmes ouverts , 116 problèmes fermés / 700 pull requests fusionnées (17 %),
- 339 fichiers changés, 46 k insertions, 23 k délétions (net : +23 k lignes),
- 3.6 (Juin 2021)
- 759 problèmes ouverts , 290 problèmes fermés / 954 pull requests fusionnées (30 %),
- 433 fichiers changés, 53 k insertions, 28 k délétions (net : +25 k lignes),
- 3.8 (Décembre 2021)
- 789 problèmes ouverts , 265 problèmes fermés / 571 pull requests fusionnées (46 %),
- 438 fichiers changés, 41 k insertions, 21 k délétions (net : +20 k lignes),
- 4.0 (Juin 2022)
- 632 problèmes ouverts , 123 problèmes fermés / 586 pull requests fusionnées (21 %),
- 359 fichiers changés, 30 k insertions, 15 k délétions (net : +15 k lignes)
- 4.2 (Décembre 2022)
- 595 problèmes ouverts , 60 problèmes fermés / 409 pull requests fusionnées (15 %),
- 336 fichiers changés, 14 k insertions, 25 k délétions (net : -11 k lignes)
- (délétions sont principalement dûes au retrait de la variante SSE2 du code de pixels, pénalisant la performance des processeurs typiques Intel i5/i7 au profit des AMD Threadripper),
- 4.4 (Juin 2023)
- 500 problèmes ouverts , 97 problèmes fermés / 813 pull requests fusionnées (12 %),
- 479 fichiers changés, 57 k insertions, 41 k délétions (net : +16 k lignes)
Pour rendre les choses plus faciles à comparer, annualisons :
- 2019 : 1049 nouveaux problèmes, 66 fermés, 88 k changements, +44 k lignes,
- 2020 : 2009 nouveaux problèmes, 208 fermés, 166 k changements, +25 k lignes,
- 2021 : 1548 nouveaux problèmes, 555 fermés, 143 k changements, +45 k lignes,
- 2022 : 1227 nouveaux problèmes, 183 fermés, 84 k changements, +4 k lignes.
Il semble que je ne sois pas le seul à trouver les bugs de 2022 plus difficiles à attaquer puisque le nombre de corrections est significativement plus faible qu’en 2021, et la tendance se maintient pour 2023. Le ratio entre les pull requests (travail effectué) et les problèmes fermés (problèmes résolus) est simplement ridicule.
Entre Darktable 3.0 et 4.0, le code d’interface graphique a grossi de 53 %, passant de 49 k à 75 k lignes3, et atteint 79 k lignes dans 4.4. En laissant de côté sa piètre qualité, je ne suis vraiment pas sûr que l’utilisabilité du logiciel ait été améliorée de 53 %. En fait, je suis convaincu du contraire. Dans Ansel, jusqu’à présent, j’ai réduit le code d’interface à 53 k lignes en retirant très peu de fonctionnalités.
Tout ça est juste trop, trop vite pour une poignée de dilettantes travaillant les soirs et les week-ends sans organisation ni planning. L’équipe Darktable travaille contre elle-même avec les yeux plus grands que le ventre, en essayant de prendre en charge trop d’options différentes, produisant du code dont le résultat de l’exécution dépend de trop de variables d’environnement, pouvant interagir de trop de manières différentes. Tout ça pour éviter de prendre des décisions de design qui pourraient en froisser certains en limitant les fonctionnalités et les options disponibles. Côté utilisateur final, le résultat est des bugs contextuels impossibles à reproduire sur d’autres systèmes, donc impossibles à régler tout court.
C’est simple : le travail effectué coûte de plus en plus de travail, et la maintenance n’est même pas assurée, comme le montre le déclin du nombre de bugs réglés. Dans une entreprise, c’est le moment où on devrait arrêter l’hémorragie avant d’avoir complètement vidé les caisses. Mais une équipe d’amateurs tenus à aucun résultat peut endurer une perte infinie. Seulement le travail généré par le travail devient de plus en plus pénible, frustrant et difficile à mesure que le temps passe, et les utilisateurs finaux sont tenus en ôtage d’une bande de salopards égocentriques et en paient le prix au niveau de la complexification de l’interface graphique, de la charge CPU inutile et du besoin de réapprendre comment effetctuer des tâches basiques avec le logiciel au moins une fois par an.
En fait, je m’attends à ce que l’équipe de destruction massive actuelle se trouve opportunément de moins en moins de temps libre pour contribuer au projet à mesure qu’ils réalisent qu’ils se sont fourrés dans une impasse avec un semi-remorque, en laissant leur merde aux suivants. Mais plus tôt ils baisseront les bras et moins de dommages ils causeront.
La débauche d’options et de préférences, qui est la stratégie Darktable pour (ne pas) gérer les désaccords sur le design à adopter, créent des cas d’utilisation ultra-contextuels où aucun utilisateur n’a les même options activées et où il est impossible de reproduire les bugs dans un environnement différent. Et demander aux utilisateurs d’attacher leur fichier de configuration darktablerc aux rapports de bugs n’aideraient pas non plus les développeurs car ce fichier fait maintenant 1287 lignes globalement illisibles.
Les bugs bizarres et difficiles à reproduire s’empilent, y compris sur des ordinateurs System 76 pourtant conçus spécialement pour Linux, où l’on ne pourra pas invoquer de problèmes de pilotes. De nombreux bugs incohérents et aléatoires que j’ai constaté en donnant des cours de retouche ne sont pas répertoriés sur le trackeur de bug, et il est à peu près clair qu’ils dorment dans les méandres de la débauche de if et switch case qui sont ajoutés à un rythme alarmant depuis 2020.
Régler ces bugs étranges et contextuels ne peut se faire qu’en simplifiant la séquence de contrôle du programme et donc en limitant le nombre d’options utilisateur. Mais la brochette de geeks qui s’agite sur le projet ne veut pas en entendre parler et, pire, les « corrections » de bugs ne font généralement qu’ajouter encore plus de lignes pour gérer séparément les cas pathologiques.
En fait, Darktable soufre de plusieurs problèmes :
1. Un noyau dur de développeurs assez médiocres mais disposant de beaucoup de temps libre pour faire n’importe quoi, animés par les meilleures intentions du monde mais sans conscience des dommages qu’ils causent, (les gens médiocres sont toujours les plus disponibles) 1. La complaisance du mainteneur, qui laisse passer du code dégueulasse pour être sympa, 1. Un manque cruel de compétences en mathématiques pures, algorithmique, traitement de signal, sciences de la couleur et généralement en raisonnement et abstraction, qui sont requises au delà du code de traitement de pixels pour simplifier et factoriser les fonctionnalités, 1. Une sale manie de “développer” par copié-collé de code récupéré ailleurs dans Darktable ou dans d’autres projets libres qui utilisent des architectures de pipeline différentes mais sans l’adapter en conséquence (pour adapter, il faut comprendre comment ça marche, et ça c’est trop demander…). 1. Un refus pur et simple de supprimer des fonctionnalités pour faire de la place aux nouvelles et garder un certain équilibre, 1. Un biais d’échantillon, où les seuls utilisateurs qui interagissent avec le développement via Github sont programmeurs et anglophones. Le fait est que le commun des mortels ne comprend pas ce qu’est une forge logicielle et qu’il est difficile d’encourager les non-programmeurs à créer un compte Github pour remonter les bugs. On parle d’une population d’utilisateurs composée à plus de 44 % de programmeurs et à plus de 35 % de titulaires d’un diplôme universitaire (ils sont respectivement 6 % et 15 % dans la population générale). 6. Un développement à marche forcée, sans agenda, sans concertation, où chaque utilisateur de Github peut polluer les discussions avec un avis non-éclairé sur les travaux en cours. Le fait est que le traitement d’image paraît facile et est sans danger, si bien que toute personne capable de calculer un logarithme se sent compétente. Mais les erreurs fondamentales dans la chaîne colorimétrique de Darktable prouvent chaque jour le contraire… 7. Une absence de priorité dans les fonctionnalités à refactoriser, stabiliser ou étendre : tous les projets sont ouverts en même temps, même s’ils entrent en conflits les uns avec les autres. 8. Une quantité d’activité (emails et notifications) impossible à suivre, entre les commentaires, les discussions hors-sujet, les bugs qui n’en sont pas, les propositions de changement de code et les changements effectifs qui peuvent impacter votre propre travail, ce qui fait qu’il faut être partout tout le temps ; il y a énormément à lire mais peu à garder, la discussion pour la discussion grève la productivité, et l’absence de structure de travail en est la cause principale. 9. des bugs non-bloquants dissimulés à la hâte avant de les avoir compris, au lieu de les régler pour de bon à la source, qui déplacent voire aggravent les problèmes à long terme sans laisser de traces dans une documentation pérenne, 10. un calendrier de sortie de version qu’on tient coûte que coûte même quand ce n’est pas réaliste, alors que personne ne nous l’impose, 11. des changements de code qui peuvent arriver partout tout le temps, qui font qu’on travaille sur des sables mouvants en permanence et qu’il faut travailler aussi vite et mal que les autres pour ne pas se retrouver largué derrière le volume et la fréquence des changements (commits), 12. des nouvelles fonctionnalités qui dégradent l’utilisabilité et complexifient l’interface sans régler de problème défini et tiennent lieu de projets récréatifs à des programmeurs non formés à la conception/ingéniérie.
Mais le plus rageant, c’est cette obstination à vouloir remplacer des fonctionnalités simples et fonctionnelles par des horreurs de sur-ingéniérie destinées à satisfaire des usages déviants et marginaux en emmerdant tout le monde avec des listes interminables d’options mal pensées. Le meilleur endroit pour cacher un arbre, c’est au milieu de la forêt, et beaucoup ne l’ont pas encore compris.
Confondre agitation et activité
Tout électeur se plait à critiquer la déviance qui, en politique, consiste à faire passer des lois de circonstance mal écrites pour calmer l’opinion suite à un événement spécial, pour montrer qu’on agit, alors que des lois similaires existent déjà et qu’elles ne sont pas ou mal appliquées faute de moyens. On appelle ça s’agiter : ça a l’apparence de l’action, ça fait le bruit de l’action, ça a le coût de l’action, mais ça ne débouche sur rien de tangible ou de pratique.
L’équipe d’amateurs sans gestion de projet qui s’agite sur Darktable ne produit que des problèmes futurs. Par le passé, Darktable sortait une fois par an avec environ 1500 à 2000 commits de plus que la version précédente. C’est désormais le volume de changements atteints en 6 mois. Un volume de “travail” qui augmente aussi vite et qui ne s’accompagne pas de méthodes de travail en groupe, incluant des priorités claires pour chaque version et une répartition des tâches, et sans validation de la qualité du logiciel basée sur des métriques objectives (nombres d’étapes ou temps nécessaire pour accomplir une action donnée), c’est simplement des mecs qui se marchent sur les pieds en poussant leur propre agenda sans se soucier ni des autres, ni du projet, ni des utilisateurs.
Darktable est devenu le club informatique du lycée, là où les geeks s’amusent. C’est globalement un condensé de toutes les pires histoires d’entreprises informatiques à ceci près que le projet ne génère pas un centime, donc il est urgent de se demander pourquoi on s’impose ça : personne n’en partage les bénéfices, mais tout le monde en subit le coût. C’est un environnement de travail chaotique, malsain, et qui ne fabriquerait que du burn-out si les amateurs à temps partiel avait des obligations de résultat et travaillaient à temps complet. Étant le seul mec à temps plein là dessus, je vous laisse imaginer la quantité de stress et d’énergie perdue pour seulement rester à jour avec la cacophonie permanente, seulement pour être sûr de ne pas manquer les 2 % qui me concernent réellement dans la quantité de bruit que des discussions dérégulées produisent.
Côté utilisateur, on salue l’effervescence du projet Darktable (oui, ça bouge), sans se rendre compte que l’emballement des commits n’est pas de l’activité mais de l’agitation, et en particulier de la dette technique qui sera payée on ne sait pas quand par on ne sait pas qui. La beauté d’un projet où personne ne doit assumer les conséquences de ses conneries puisque personne n’est responsable de rien : c’est écrit dans la licence GNU/GPL. On peut donc saloper allègrement le travail des précédents en toute impunité.
On a bien un semblant de contrôle qualité, via les tests d’intégration, qui mesurent l’erreur perceptuelle sur des traitements photo de référence, mais ils ne déclenchent même plus d’émotion quand on voit une erreur moyenne sur une image d’un delta E de 1.3 (faible) alors que la nature du changement apporté aurait dû avoir un delta E strictement nul. Si le test passe (parce qu’on ne teste qu’une image SDR sur une scène studio), on ne cherche pas à comprendre ni à valider si la théorie tient debout. On a transformé le test en décharge de responsabilité, tant que la métrique d’erreur reste sous le seuil de validation…
Avec la sortie de darktable 4.0 — Geektable —, j’ai vu sur Youtube les gens commencer à se plaindre que cette release n’était pas très excitante. À force de droguer nos utilisateurs à la release superlative, blindée de fonctionnalités qu’on n’a pas eu le temps de tester correctement (6-8 gars qui pissent 38-50 k lignes de code tous les 6 mois en ne bossant que les soirs et week-ends, vous rêvez encore ?), on en a fait des accros au sapin de Noël blindé pour être sûr que, le jour où l’envie nous prend d’être enfin responsables et de sortir des versions stables (donc ennuyeuses), ça se retournera contre nous.
La raison de ce rythme effréné de sortie de version est que les pull requests de plus de 3 mois sont invariablement en conflit avec la branche principale, vue que celle-ci est secouée tous les mois pour “des tests généralisés”. Sauf que les rares utilisateurs qui compilent la branche principale (master) n’ont pas la moindre idée de ce qu’il faut tester en particulier, à moins de disséquer l’historique des commits Git, ce qui implique de comprendre à la fois le langage C et l’impact des changements en pratique sur le logiciel.
Pour limiter les branches à durée de vie trop longue, qui finiront invariablement en conflit avec la branche principale, on a trouvé une solution brillante : on sort 2 releases par an, faisant du développement à marche forcée à base de code pas fini et peu testé un art de vivre, sans jamais réaliser que le problème de fond, c’est d’abord l’absence de planification, mais aussi le fait que les contributeurs codent avant d’avoir défini le problème à résoudre (quand il y a un vrai problème à résoudre, et pas juste un mec qui s’est dit que “ça serait cool si…”), en modifiant en parallèle les mêmes parties, sans concertation.
La poussière n’a pas le temps de retomber qu’on est déjà en train de secouer à nouveau la base de code, sans jamais se donner de phases de stabilisation où l’on ne fait que nettoyer les bugs (et je ne parle pas du mois de feature-freeze avant la release, mais de releases consacrées seulement à l’amélioration du code). Le trackeur de bugs explose dans les 3 semaines suivant chaque release, puisqu’une part significative des utilisateurs n’utilisent que les paquets pré-compilés, ce qui coïncide en plus avec les vacances d’été et les vacances de Noël, où j’ai personnellement autre chose à faire que me taper des rapports de bugs après le sprint épuisant que représente le mois précédent les releases.
Depuis 2021, quand je mets à jour mon dépôt Git avec les derniers changements de la branche master de Darktable, c’est en me demandant ce qu’ils ont encore cassés cette fois ci. On casse plus vite qu’on ne répare et généralement, les réparations cassent autre chose. En fait, les seuls utilisateurs qui trouvent Darktable stable sont ceux qui en font une utilisation très basique, ce qui est ironique pour une application dont l’argument de vente est précisément d’être avancée.
Alors on me sert le fait que c’est du travail gratuit, comme si c’était une excuse. En fait, c’est une circonstance aggravante : si ce n’est pas payé, pourquoi on s’impose des conditions de travail comme celles-là ??? En dehors du fait que ce travail gratuit me colle un burn-out post-release par an, il coûte de plus en plus cher en maintenance et la maintenance est de plus en plus désagréable. Ce n’est pas du travail gratuit, c’est pire : c’est du travail qui coûte sans rapporter.
De plus, il est fourni par des gens qui ont un temps et une énergie limités. Si la ressource est limitée, il va falloir arrêter de me raconter des histoires : on est dans les mêmes contraintes de rentabilité qu’une entreprise, les cotisations sociales en moins, à la différence que notre monnaie est du temps et qu’il n’est pas remboursable. Sans gestion des priorités, on va se faire dépasser par de la dette technique qu’on n’aura pas les ressources pour maintenir.
Qu’est-ce qu’on attend pour être heureux ?
Le fait que Darktable soit un rouleau compresseur en plein emballement et sans pilote, qui génère une quantité de travail croissante, n’est pas bon signe pour un projet qui approche des 15 ans. Normalement, un projet mature ralentit le rythme parce qu’il est assez complet pour être utilisable et que les gens qui bossent dessus ont trouvé un rythme de croisière et des méthodes de travail efficaces.
Je suis dessus à temps plein depuis le 2018, pour des revenus qui s’étalent entre 800 et 900 € par mois, et c’est peu dire que c’est mal payé pour endurer les conséquences désastreuses du travail d’amateurs désorganisés qui veulent juste participer à quelque chose qu’ils trouvent cool au mépris de la qualité du produit fini et de son utilisabilité par des moldus de l’informatique. Du reste, les moldus sont méprisés aussi, par principe.
Si je baisse le nez un mois et demi pour développer un espace de couleur perceptuel, quand je relève la tête, c’est pour découvrir la nouvelle usine à gaz qui viole un peu plus le paradigme vue-modèle-contrôleur et me faire signifier que j’arrive trop tard pour m’opposer au projet. Si je prends 3 semaines de vacances en août, c’est pour découvrir que le mainteneur à court-circuité (une fois de plus) ma révision sur un changement mathématique sur ledit espace de couleur, qui suppose de s’asseoir calmement à tête reposée pour remonter le fil du calcul, tout ça parce que… fallait aller vite ? Pour quelle urgence, exactement ?
J’ai dû recevoir la notification quelque part au milieu des 2234 emails que Github m’a envoyé entre janvier et août 2022 (en 2021, c’était 4044), sans parler des utilisateurs qui me ping un peu partout, sur Youtube, Reddit, Matrix, Github, Telegram, directement par email et anciennement sur pixls.us (693 emails en 2022, 948 en 2021). Tout ça pour des gens en complet décalage, qui ne réalisent pas que je fais ça toute la semaine, que la photo est leur loisir à eux mais mon travail à moi, et que j’aimerais juste qu’on me lâche le chat les week-ends et jours fériés. Sans compter que les plus emmerdants ne sont pas ceux qui rétribuent financièrement mon travail. Les gens ne respectent le travail que s’il leur a été facturé bien cher.
Je n’ai ni le temps ni l’envie de faire chercheur, designer et en plus secrétaire, tout en faisant du baby-sitting technique au milieu d’une équipe de Gaston Lagaffe qu’il faut à la fois former et surveiller parce qu’ils sont incapables de :
- établir un planning de développement avec un ordre de priorité des nouvelles fonctionnalités sur lesquelles “on” va travailler, 2. fournir un cahier des charges des besoins et des problèmes, avec un cas d’utilisation réel, avant de se jeter sur leur éditeur de code et de faire n’importe quoi pour développer une nouvelle fonctionnalité qui se cherche un problème à résoudre,
- évaluer le coût de maintenance du changement avant d’inventer la pompe à lardons bionique à osmose inversée qui ne marche que les jours pairs si Jupiter est en quadrature inverse avec Saturne, 4. limiter les pertes et arrêter les frais quand ils s’engagent dans des impasses de design introduisant des régressions pires que les hypothétiques bénéfices attendus, 5. prendre sur soi et reculer une release si le code n’est manifestement pas prêt (ou alors je n’ai rien compris et les actionnaires vont nous virer si on release en retard ???).
Le management (ou la gestion d’équipe) est de l’overhead qui coûte du travail, mais l’équipe Darktable à atteint une échelle où le manque de management coûte en réalité plus de travail, d’autant qu’il ne reste plus un seul des fondateurs du projet dans l’équipe de développement et qu’il faut rétro-ingénier les plans de conception initiaux du logiciel à coups de grep dans le code. Si c’était supportable avec une équipe réduite où tout le monde se connaissait, Darktable est devenu un projet à fort trafic pendant les confinements Covid et cette façon de fonctionner n’est plus tenable avec ces effectifs.
Allez lire le code ! Comparez la branche darktable-2.6.x avec la darktable-4.2.x, fichier par fichier, vous m’en direz des nouvelles !
Tout ce que j’ai entendu jusqu’à présent, ce sont des phrases toutes faites comme « c’est comme beaucoup d’autres projets open source » et « nous ne pouvons rien y faire ». Les gens ont peur de la quantité de travail qu’impliquerait un fork, j’ai reçu des emails essayant de me convaincre que cela divisait la productivité, sans réaliser la quantité de ressources actuellement gaspillées par le projet Darktable et le stress permanent de devoir baser son travail sur une base de code instable constamment secouée. Jusqu’à présent, Ansel m’a coûté moins de fatigue et j’ai résolu un nombre significatif de problèmes parmi lesquels certains avaient été signalés depuis 2016 sans le moindre signe d’intérêt de la part de cette fichue « communauté ».
Sans compter qu’Ansel a des binaires pré-compilés automatiquement chaque nuit, pour Linux (.AppImage) et pour Windows (.exe), afin de permettre de vrais tests généralisés, y compris par des gens incapables de compiler du code source eux-mêmes. J’ai demandé ça en 2019 , mais apparemment les geeks ont mieux à faire, et il a fallu que j’y mette 70 h moi-même pour que ça arrive. L’opération est déjà un succès et a permis de régler en quelques jours des bugs Windows qui auraient traîné des semaines dans Darktable. (Et Darktable a récupéré 3 semaines après mon script de compilation d’AppImage sans me créditer, mais c’est un détail)
Côté productivité, je rappelle que la table lumineuse a été ré-écrite totalement 2 fois depuis 2018 (la dernière mouture n’est pas meilleure ni plus rapide) et le grand changement des filtres de collections introduit en avril 2022 a écrasé un autre changement proposant le même type de fonctionnalité (mais avec 600 lignes à la place de 6000) introduit en février 2022 (la version de février est celle disponible dans Ansel). On ne peut décemment pas parler de productivité quand le travail d’un contributeur écrase littéralement le travail précédent d’un autre dans un intervalle d’un mois, par simple faute d’une gestion de projet. On appelle ça se marcher sur les pieds.
Du coup on fait quoi pour régler le problème ? On soufre en silence ? On vit dans le déni ? On continue à régler des trucs qu’un autre cassera dans un an quand on aura de dos tourné ? On continue à faire croire aux moldus, à longueur de forums photo, que le libre c’est aussi bien que le propriétaire, tout en se gardant comme joker le fait que c’est gratuit donc t’as pas le droit de te plaindre ? C’est pas un peu facile et malhonnête, ce double discours ?
Ça vous dirait pas d’arrêter de faire passer l’habitude pour de l’expérience et le fatalisme pour de la sagesse, mais plutôt d’attaquer le problème à sa source ??? Vous ne pensez pas que vous et moi méritons mieux que du logiciel conçu par des amateurs dont le seul talent est d’avoir du temps libre et de pouvoir se permettre de bosser gratos parce qu’ils sont passés managers et que les gosses sont à la fac ?
Ou alors je me suis trompé depuis le début, et le logiciel libre, c’est donner des outils trop compliqués à des geeks qui n’en ont pas vraiment besoin, en essayant de convaincre le reste du monde que le libre n’est pas une hyper-niche pour développeur ???
Quatre ans de travail pour en arriver là
Après 4 ans à avoir bossé sur Darktable à temps plus que plein pour une paie sous 70 % du salaire minimum, et 2 ans à subir l’insatisfaction chronique d’entacher mon nom en participant à faire de la merde, j’ai forké Ansel et je ne reviendrai pas en arrière.
En 4 ans, j’ai amené à ce logiciel quelque chose qui lui manquait cruellement : un workflow de retouche unifié, à base d’un ensemble de modules conçus pour travailler ensemble, mais opérant chacun sur un aspect distinct, là où les modules de Darktable étaient plutôt une collection de plugins disparates. On parle de :
- filmique,
- l’égaliseur de tons,
- le module de flous physiques,
- les deux versions de la balance couleur,
- la calibration des couleurs, incluant l’interface de profilage par color checker directement en chambre noire et la balance des blancs par des méthodes standardisées par la Commission Internationale de l’Éclairage,
- le module négadoctor d’inversion des négatifs d’après Kodak Cineon,
- le module diffusion et netteté pour l’ajout et la suppression de flou basé sur la diffusion thermique,
- le mode “laplacien guidé” de reconstruction des hautes lumières.
J’ai développé également des outils plus fondamentaux qui ont servi de base aux précédents modules :
- un solveur d’équations différentielles anisotropiques du 4 e ordre dans le domaine des ondelettes pour le module diffusion et netteté,
- une adaptation du précédent en laplacien guidé pour la reconstruction en RGB de signaux endommagés par propagation de gradients,
- un modèle d’apparence des couleurs perceptuel prenant en compte l’effet Helmholtz-Kohlrausch dans le calcul de la saturation pour limiter l’effet “fluo” typique qui accompagne les resaturations intenses, pour le module balance couleur,
- un coup de main théorique dans le développement du filtre guidé invariant en exposition (EIGF), pour le module égaliseur de tons,
- un solveur d’équations vectorielles linéaires par la méthode de Choleski,
- différentes méthodes d’interpolations à l’ordre 2, 3, et radiales.
Dans l’interface graphique, j’ai notamment :
- refactorisé les déclarations de style, en les retirant les règles du code source C pour les mapper à la feuille de style CSS, permettant ainsi d’avoir des thèmes d’interface multiples et redéfinis par l’utilisateur,
- introduit le mode de prévisualisation focus-peaking et le mode d’évaluation des couleurs ISO 12 646 ,
- introduit le vocabulaire de couleur dans la pipette de couleur globale , permettant d’extraire le nom de la couleur à partir de ses coordonnées chromatiques, à destination des daltoniens.
Après tout ça, j’ai écrit des dizaines de pages de documentation en deux langues, publiés des articles et des dizaines d’heures de vidéo sur YouTube pour démontrer comment utiliser les modules que j’ai développé, dans quelles circonstances et pour quel bénéfice, incluant des retouches rapides en 3 à 5 modules maximum qui permettent de venir à bout de 75 à 80 % des photos, peu importe leur plage dynamique. Dans le monde libre, à part peut-être pour des projets soutenus par des fondations (comme Krita et Blender), ce niveau de support et de documentation n’existe simplement pas, et même dans le monde commercial, ce ne sont pas les développeurs qui se chargent de ce travail.
Malgré cela, je n’ai jamais dépassé 240 donateurs, à mettre en rapport avec environ 1800 répondants uniques ayant participé aux sondages Darktable de 2020 et 2022 , et qui déclarent dépenser en moyenne entre 500 et 1000 €/an pour leur photographie.
Je ne vais pas les regarder détruire l’utilisabilité de ce logiciel en essayant de me convaincre que c’est le progrès et qu’on n’y peut rien. En fait de progrès, c’est la vision délirante du progrès vu par une bande de quinquagénaires dilettantes. Depuis 2 ans, je ronge mon frein, en fermant ma gueule pour être sympa, mais en regardant la dégradation des fonctionnalités de base, complexifiées pour supporter des lubies de développeur fou, je pense que j’aurais mieux fait d’être désagréable plus tôt. Être sympa n’a rien réglé puisque la tendance, non seulement se poursuit, mais en plus s’accélère et il n’y aura pas de prise de conscience avant le point de non retour. On ne peut pas attendre de ceux qui sont à la source des problèmes de les régler.
Et quitte à travailler pour une « communauté » intéressée principalement par la gratuité du logiciel, qui a décidé que mon travail ne valait pas le salaire minimum, ça sera selon mes termes et mes standards.
En terme de fonctionnalités, Darktable a déjà beaucoup trop et il faut couper. Depuis 10 ans que je l’utilise, il a toujours été blindé de trucs mal foutus. Le challenge aujourd’hui, c’est présenter les fonctionnalités intelligemment, et régler les bugs gênants avant que ces andouilles en introduisent des nouveaux, voire ne les règlent à leur manière : en cachant la poussière sous le tapis. En sachant que le pipeline graphique de Darktable a 15 ans, et qu’on ne pourra pas l’optimiser beaucoup plus que ça, d’autant qu’il a été déjà bien torturé pour éviter une réécriture complète (et qu’une réécriture complète du pipeline n’aurait pas d’avantage si on doit garder Gtk comme librairie graphique puisque c’est la principale perte de performance).
Les solutions dont Darktable a besoin impliquent de retirer du code et des options, pas d’en ajouter toujours plus. La robustesse est à ce prix. L’équipe Darktable fait exactement l’inverse et n’apprend pas de ses erreurs.
Avec Ansel, je veux un moyen de finir ce travail sereinement pour que les utilisateurs de Linux ait un outil fiable, cohérent et performant pour leur photographie artistique. Avant de passer à Vkdt parce que le design actuel montre ses limites.
Translated from English by : Aurélien Pierre, ChatGPT, Claude. In case of conflict, inconsistency or error, the English version shall prevail.
By the way, I can no longer bare the attempt of being different for the sake of it by writing “Darktable”, proper noun, without initial capital. It’s childish, it’s neither funny or disruptive, and it makes a mess of freedesktop.org menus where the capital is anyway added to follow the standard. ↩︎
The fact that bugfixes systematically add more lines of code instead of modifying existing lines is a a concerning smell that the programming logic is bad and induces too many particular cases. Rigorous programmers always try to keep their code as generic as possible to avoid spaghetti code . ↩︎
git checkout release-3.0.0 & cloc $(git ls-files -- 'src/views' 'src/gui' 'src/bauhaus' 'src/dtgtk' 'src/libs')↩︎
